资源下载
资源下载
假设你正在设计一种ML工具,这个工具会尝试根据医学数据将患者分为两类:“应由医生检查是否患有癌症”和“不应该接受检查”这两个类别。
接受过该工具训练的患者数据仅包含有关癌症危险因素的信息(家族病史,年龄,体重,这类事情),而没有足够的信息来准确判断一个人是否患有癌症。训练数据还包含患者是否最终患有癌症,以便ML工具可以学会区分两组。
由于此信息不完善,该工具为患者分配了0到1之间的分数-分数越高,该工具就越有信心认为患者有患癌症的风险。
对该工具进行训练后,就可以评估其有效性。对此有几种测量方法,例如,假阳性率(建议对未患病的人进行检查)和假阴性率(不建议对癌症患者进行进一步检查)。这两个都是我们希望最大程度地降低的不良结果,但并非同样糟糕。
然而,在你测量这些东西之前,你可以选择使用什么阈值分数来决定患者是否接受其他检查?毕竟,每个使用该工具得分不为零的患者都有患癌症的风险,因此有理由对每个人进行测试。
但是我们要构建此工具的原因是因为可以避免这样做,因为测试成本很高,而且如果我们测试每个人的误报率都很高,我们将测试很多不需要测试的人。测试每个人对应的阈值就非常低。
另一方面,我们可能只建议极有癌症风险的人进行检查,这样我们的假阳性率会很低(几乎每个接受检查的人都需要检查),但是我们也会有很多假阴性,会让很多未经测试的癌症患者回家。这就对应于具有非常高的阈值得分。
那么,如何比较阈值,并确定哪个阈值最适合你的工具?可以通过绘制ROC曲线得知。
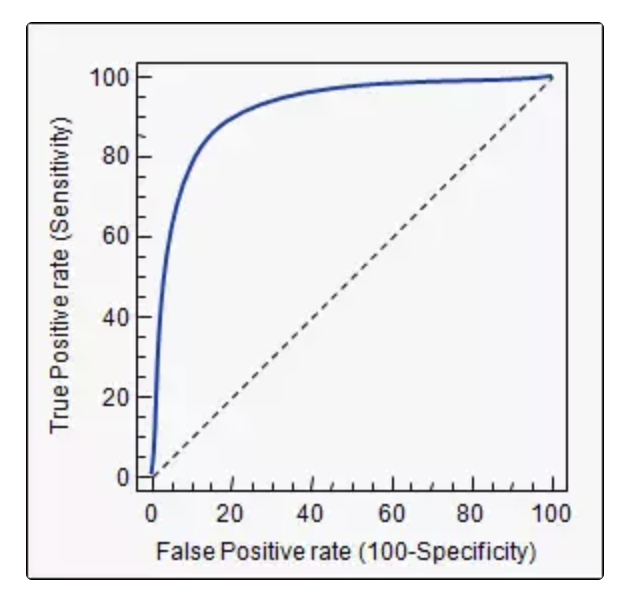 当选择一个阈值时,你可以让工具使用该阈值对测试数据集进行分类,并计算得出的假阳性率和真阳性率。这让我们在ROC曲线上获得了一个点。
当将阈值从高变低时,真实的阳性率会增加(测试确实有癌症的人的比例更高),而错误的阳性率也会增加(错误地告诉更多的人在他们没有患病时接受测试)。
当从高到低逐步遍历阈值时,将点从左到右放在上面的图形上,把这些点连接起来可得出ROC曲线。
虚线是随机分类器可以实现的目标,例如为每位患者投掷硬币,假阳性与真阳性一样多。曲线越靠近左上角,则ML工具就越能更好地区分这两个类别。
要决定使用哪个阈值,仅靠ROC曲线是不够的,即使该工具在阈值0.6时最具预测性,我们还是希望用0.4分及以上的分数测试每个人,因为假阴性(癌症患者失踪)比假阳性要严重(不必要地测试患者)。
当选择一个阈值时,你可以让工具使用该阈值对测试数据集进行分类,并计算得出的假阳性率和真阳性率。这让我们在ROC曲线上获得了一个点。
当将阈值从高变低时,真实的阳性率会增加(测试确实有癌症的人的比例更高),而错误的阳性率也会增加(错误地告诉更多的人在他们没有患病时接受测试)。
当从高到低逐步遍历阈值时,将点从左到右放在上面的图形上,把这些点连接起来可得出ROC曲线。
虚线是随机分类器可以实现的目标,例如为每位患者投掷硬币,假阳性与真阳性一样多。曲线越靠近左上角,则ML工具就越能更好地区分这两个类别。
要决定使用哪个阈值,仅靠ROC曲线是不够的,即使该工具在阈值0.6时最具预测性,我们还是希望用0.4分及以上的分数测试每个人,因为假阴性(癌症患者失踪)比假阳性要严重(不必要地测试患者)。
机器学习中的ROC曲线是什么?
0 1041
1
该提问暂无详细描述
收藏
共 1 个回答
高赞 时间
0
收藏