资源下载
资源下载
0
通常,我们将数据集划分为训练集和测试集。然后,对训练集调用拟合方法建立模型,并将模型应用于测试集,估计目标值,评价模型的性能。我们将数据分为训练集和测试集的原因是使用测试集来估计模型在训练数据上的训练效果,以及在未知的数据上的表现。
然而,交叉验证是一种方法,它超越了使用单个序列和数据的测试分割来评估单个模型。它应用于使用训练数据集创建的更多子集,每个子集用于训练和评估单独的模型。也就是说,我们将训练数据集分成k个子集,第i个模型将建立在除第i个子集以外的所有子集的并集上。然后在第i部分测试模型i的性能。
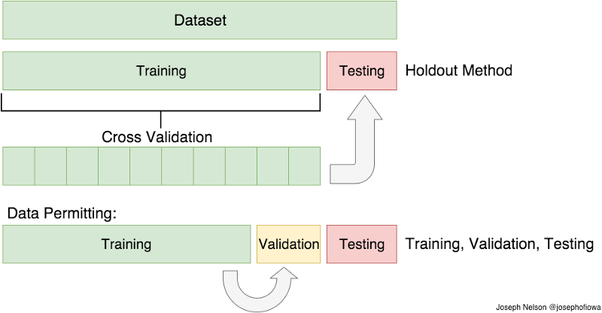 那么,为什么这比我们最初的单列训练和测试分离的方法更好呢?
通过为训练和测试数据分割选择不同的长度,模型性能会有很大的变化,这取决于碰巧在训练集中结束的特定样本。交叉验证为模型的平均性能提供了更稳定的估计,而不是完全依赖于单个训练集。
最常见的交叉验证技术是k-层交叉验证。为了进行五重交叉验证,将训练数据集划分为大小相等或接近相等的五个部分。每一部分都被称为“层”。第一个模型使用层1到4进行训练,并在层5上进行评估。第二个模型使用层1、2、3和5进行训练,并对层4进行评估,依此类推。完成这个过程后,我们有五个精度值,每个模型一个。然后计算所有准确度的平均值和标准差,并用它来比较我们期望模型的平均准确度。
那么,为什么这比我们最初的单列训练和测试分离的方法更好呢?
通过为训练和测试数据分割选择不同的长度,模型性能会有很大的变化,这取决于碰巧在训练集中结束的特定样本。交叉验证为模型的平均性能提供了更稳定的估计,而不是完全依赖于单个训练集。
最常见的交叉验证技术是k-层交叉验证。为了进行五重交叉验证,将训练数据集划分为大小相等或接近相等的五个部分。每一部分都被称为“层”。第一个模型使用层1到4进行训练,并在层5上进行评估。第二个模型使用层1、2、3和5进行训练,并对层4进行评估,依此类推。完成这个过程后,我们有五个精度值,每个模型一个。然后计算所有准确度的平均值和标准差,并用它来比较我们期望模型的平均准确度。
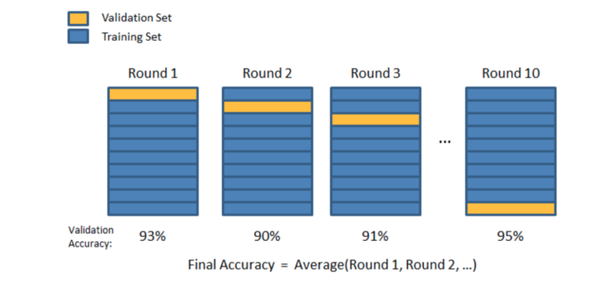 我们如何选择层的数量?层数量的选择必须满足每个验证分区的大小足够大,以提供模型在其上的性能的公平估计,并且不应太小。
我们如何选择层的数量?层数量的选择必须满足每个验证分区的大小足够大,以提供模型在其上的性能的公平估计,并且不应太小。
收藏