资源下载
资源下载
离线训练的推荐系统架构是最常见的一种推荐系统架构。这里的“离线”训练指的是使用历史一段时间( 比如周或者几周 )的数据进行训练,模型迭代的周期较长(一般以小时为单位 )。模型拟合的是用户的中长期兴趣。
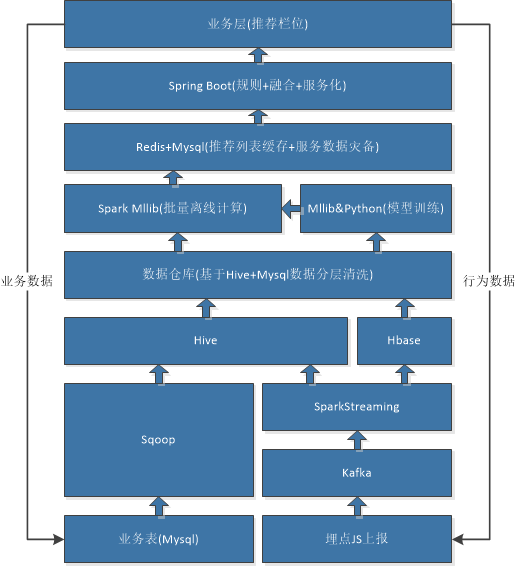
如下图所示,一个典型的基于离线训练的推荐系统架构由数据上报、离线训练、在线存储、实时计算和 A/B 测试这几个模块组成。其中,数据上报和离线训练组成了监督学习中的学习系统,而实时计算和 A/B 测试组成了预测系统。另外,除了模型之外,还有一个在线存储模块,用于存储模型和模型需要的特征信息供实时计算模块调用。图中的各个模块组成了训练和预测两条数据流,训练的数据流搜集业务的数据最后生成模型存储于在线存储模块;预测的数据流接受业务的预测请求,通过 A/B 测试模块访问实时计算模块获取预测结果。

- 数据上报:据上报模块的作用是搜集业务数据组成训练样本。一般分为收集、验证、清洗和转换几个步骤。将收集的数据转化为训练所需要的样本格式,保存到离线存储模块。

离线训练:线训练模块又细分为离线存储和离线计算。实际业务中使用的推荐系统一般都需要处理海量的用户行为数据,所以离线存储模块需要有一个分布式的文件系统或者存储平台来存储这些数据。离线计算常见的操作有:样本抽样、特征工程、模型训练、相似度计算等。
在线存储:因为线上的服务对于时延都有严格的要求。比如,某个用户打开手机 APP ,他肯定希望APP 能够快速响应,如果耗时过长,就会影响用户的体验。一般来说,这就要求推荐系统在几十毫秒以内处理完用户请求返回推荐结果,所以,针对线上的服务,需要有一个专门的在线存储模块,负责存储用于线上的模型和特征数据 。
实时推荐:实时推荐模块的功能是对来自业务的新请求进行预测。1.获取用户特征;2.调用推荐模型;3.结果排序。
在实际应用中,因为业务的物品列表太大,如果实时计算对每 个物品使用复杂的模型进行打分,就有可能耗时过长而影响用户满意度。所以,一种常见的做法是将推荐列表生成分为召回和排序两步。召回的作用是从大量的候选物品中(例如上百万)筛选出一批用户较可能喜欢的候选集 (一般是几百)。排序的作用是对召回得到的相对较小的候选集使用排序模型进行打分。更进一步,在排序得到推荐列表后,为了多样性和运营的一些考虑,还会加上第三步重排过滤,用于对精排后的推荐列表进行处理。

- A/B测试:对于互联网产品来说, A/B 测试基本上是一个必备的模块,对于推荐系统来说也不例外,它可以帮助开发人员评估新算法对客户行为的影响。除了 离线的指标外,一个新的推荐算法上线之前 般都会经过 A/B 测试来测试新算法的有效性。
下图是与之对应的实际系统中各个组件的流转过程。需要注意的是生成推荐列表就已经做完了召回和排序的操作,业务层直接调用API就可以得到这个推荐列表。
下面是一个供参考的离线推荐系统的模块结构