 资源下载
资源下载



【项目】深层文本匹配

文件列表(压缩包大小 18.35M)
免费
概述
深层文本匹配
项目模型
环境准备
tensorflow >= 1.14 (1.x版本)
keras >= 2.3.1
运行
运行一般深度神经网络模型
#运行cdssm模型 #进入text_match文件夹路劲 python word2vec_static.py #训练词向量,仅在第一次运行本项目的模型时需要 python train.py cdssm运行 bert 系列模型
#安装bert4keras 库 pip install bert4keras # 自行准备预训练模型的权重文件和配置文件 # 进入bert_model文件夹 # 修改函数 build_transformer_model 中 ‘model’参数 python bert_similarly.py
使用自己的数据训练
- 将自己的数据集处理成 header 为 sentence1,sentence2,label 三个字段的csv文件,如下图所示:

将数据分为 train.cav,dev.csv ,test.csv 放入 ./input 文件夹中。
- 自己重写数据预处理脚本
设置参数
在train.py脚本里的相应位置设置相应模型的参数。
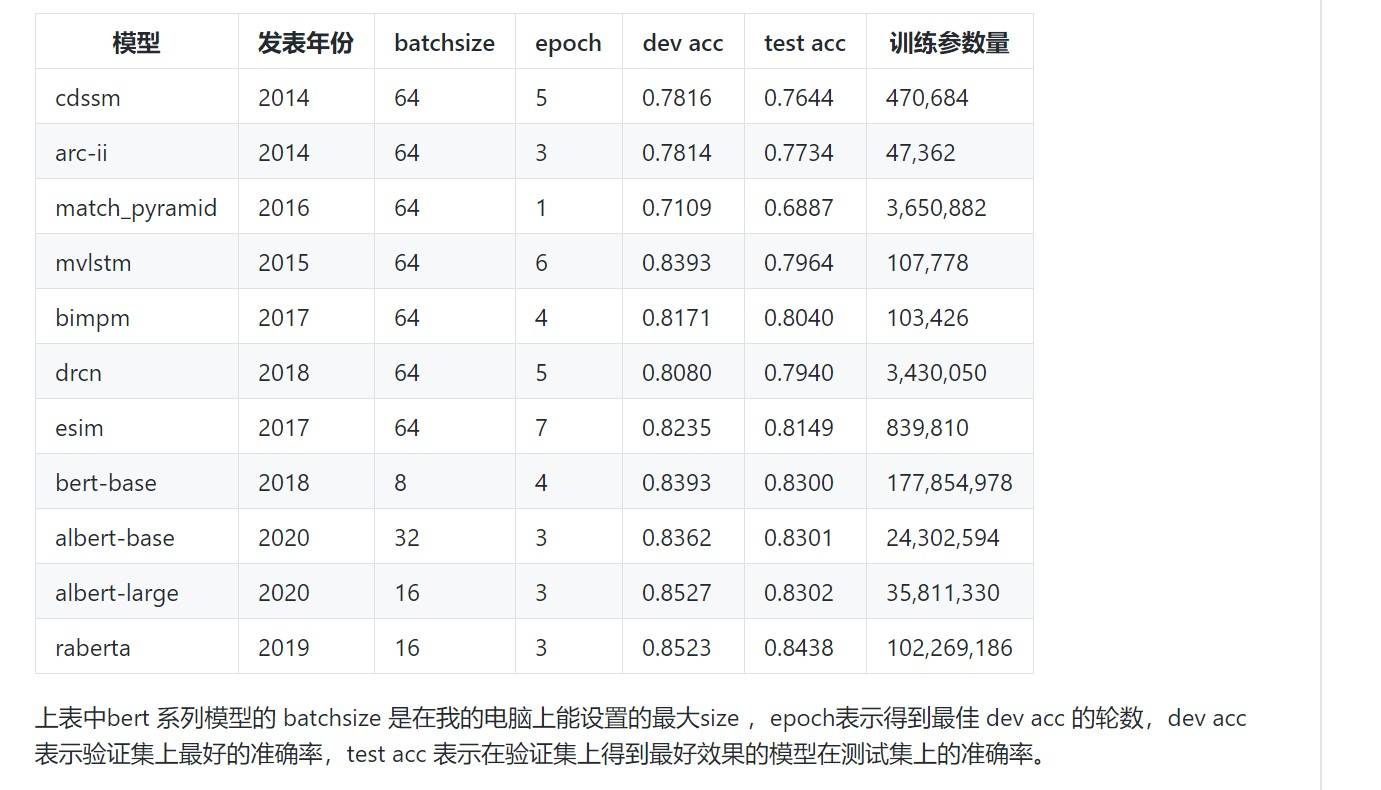
实验结果分析
毫无疑问 bert 系列模型的效果最好,由于我的电脑不允许我使用较大的batchsize进行训练,因此上文表格中报道的准确率不是最佳准确率,如果加大batchsize 应该能提升效果的;另外使用 rnn 做encode 的模型效果明显好于使用cnn 做 encode 的模型。
文本匹配模型一般分为表示型和交互型模型,为了下文方便描述,我将文本匹配模型的框架分为三个层,分别是 Embedding 层,Encoding 层(在交互型模型里,该层还包含匹配层), Prediction 层如下所示:
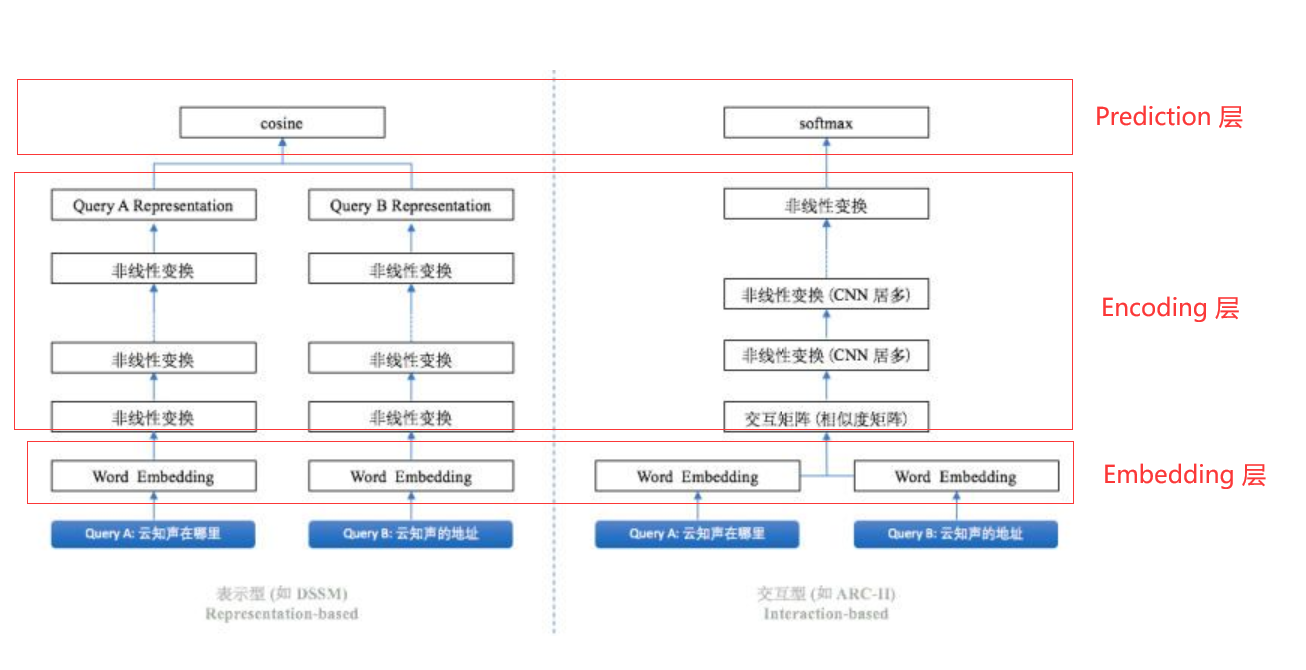
Encoding 层参数共享与不共享
由于模型需要对输入的左右两个句子进行建模,因此需要编码器分别对两个句子进行编码,我们可以选择是否共享左右编码器的参数,下面两段代码分别表示不共享与共享的写法。
rep_left = keras.layers.Bidirectional(keras.layers.LSTM(
self._params['lstm_units'],
return_sequences=True,
dropout=self._params['dropout_rate']
))(embed_left)rep_right = keras.layers.Bidirectional(keras.layers.LSTM(
self._params['lstm_units'],
return_sequences=True,
dropout=self._params['dropout_rate']
))(embed_right)
bilstm = keras.layers.Bidirectional(keras.layers.LSTM(
self._params['lstm_units'],
return_sequences=True,
dropout=self._params['dropout_rate']
))rep_left = bilstm(embed_left)rep_right = bilstm(embed_right)
不共享参数的情况其实就是分别初始化两个双向LSTM网络,然后分别对左右两个句子进行编码;而共享参数是只初始化一个双向LSTM网络,然后左右句子都使用它来编码。在计算文本相似度这个任务时,从实验中发现共享参数的编码对模型更有帮助,比如 mvlstm和 bimpm 两个模型共享Encoding 层参数比不共享参数准确率要高 7-8个百分点,这两个模型都是使用 rnn 网络做编码器的;而使用cnn 网络做编码器的 arcii 模型共享参数后比不共享参数准确率高2个百分点左右。
深度神经网络模型并不是网络层数越多效果越好
在深度学习领域其实有个经验,就是只要把网络做深效果就会更好,这也许有一定道理,但是面对不同数据,我们应该多尝试。在 arcii 模型中 3 个 cnn block(如下图的 more 2D convolution & pooling 结构)比 2 个 cnn block的模型效果要差一些(0.7734 -> 0.7684)。
产生这个结果的原因可能是所用数据集的句子基本是短句子,语句结构也不复杂的缘故。其实可以看到准确率差的也不多,但是使用 rnn 做 encode的模型在增加深度后效果将会差的更多。
如下图所示的 drcn 模型,原文中使用 4 个 Nx 模块,每个Nx 包含 5 层 LSTM,总共20 层 LSTM的网络,但是在我的实验中我发现在每个 Nx 里面只能用两层LSTM,且只能用 1个 Nx,如果再多效果反而会不好。
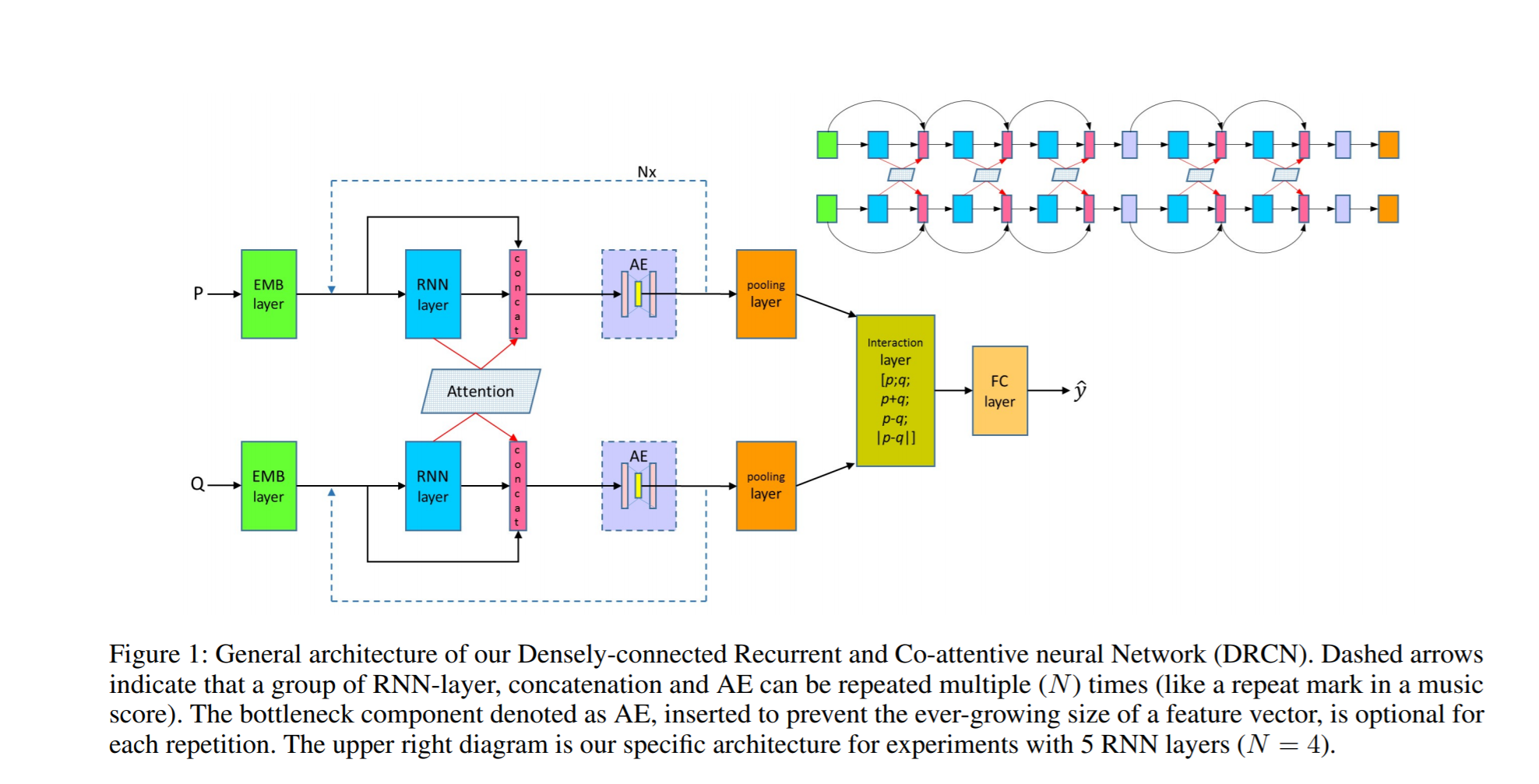
另外该模型虽然花里花俏的,但是效果并没有更朴素 bimpm 和 mvlstm 模型要好。也许是我用了 BatchNormalization 做层归一化的缘故(MatchZoo 中使用的 Dropout),但是不用 BN 的话训练时将会造成梯度爆炸。
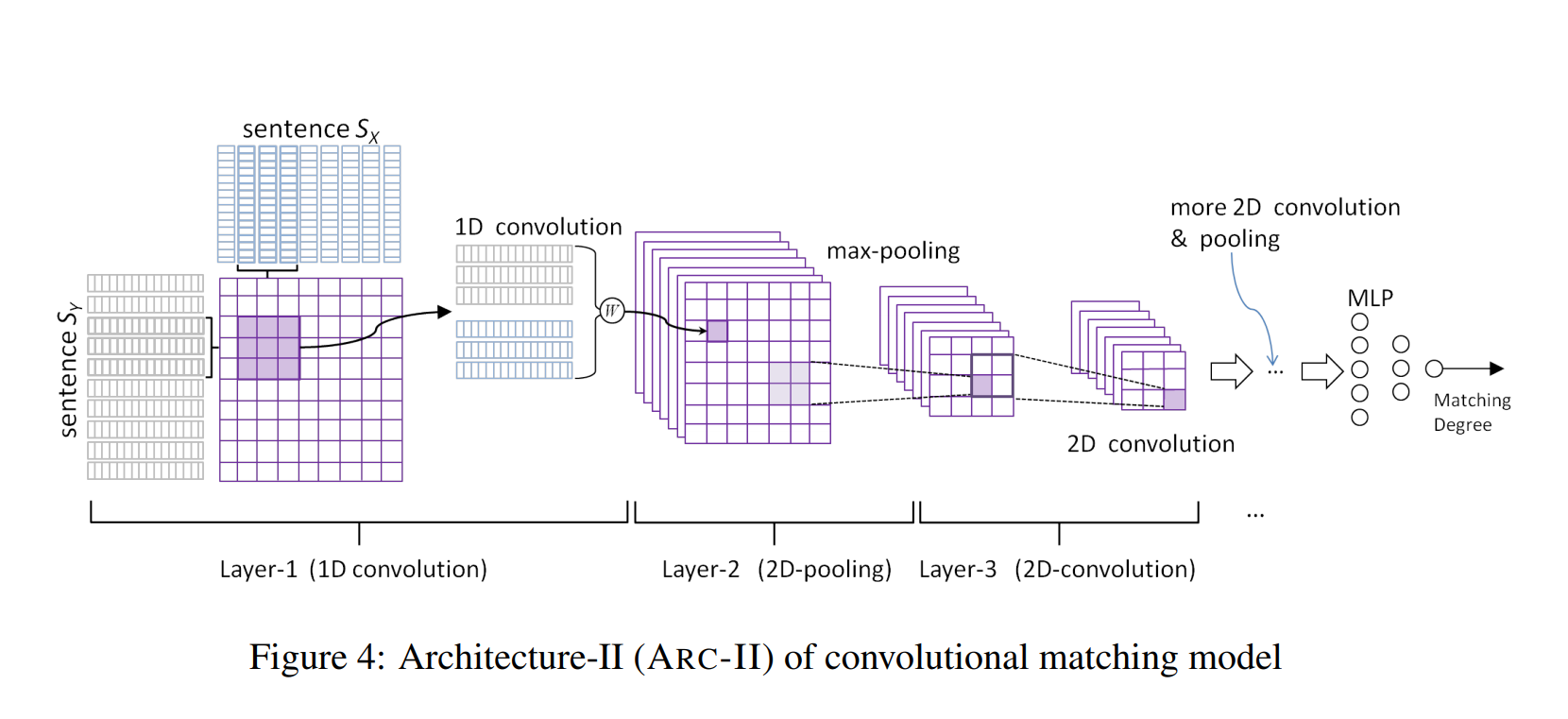
match_pyramid 和 arcii 模型
这两个模型都是使用2D convolution 做编码器提取特征的,但是为什么match_pyramid 效果这么差呢?将match_pyramid模型的结构和arcii对比一下:
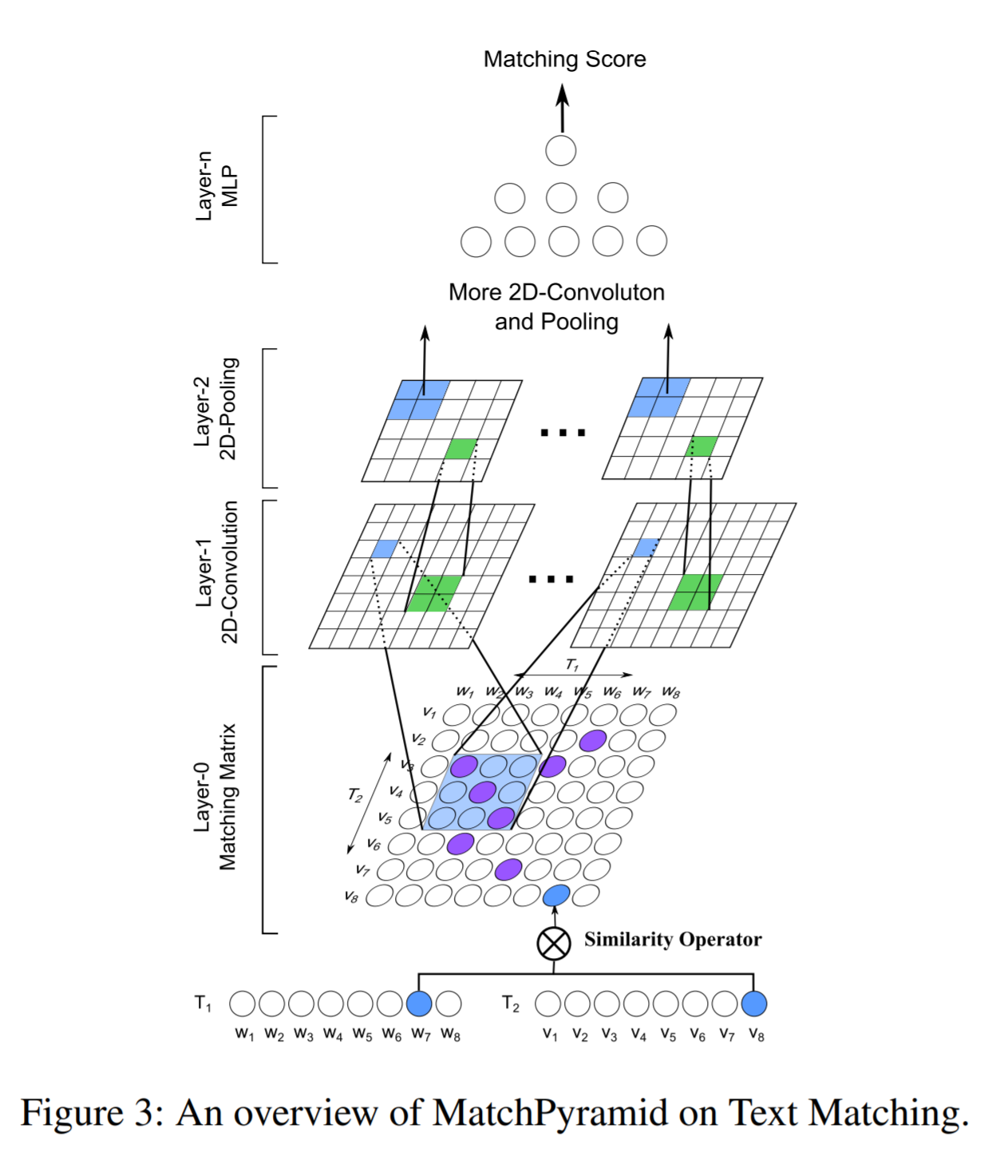
可以看到,match_pyramid直接用左右两个句子的embedding进行匹配交互,然后用 2D convolution 提取特征,这显然匹配层的好坏直接取决于 embedding的好坏;而arcii 首先使用了一层 1D convolution 对embedding进行编码,再进行匹配计算的。所以其实 match_pyramid 模型等于就是 arcii 模型的阉割版(少一层关键的 1D convolution)。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







