 资源下载
资源下载


【Demo】基于新浪微博数据的情感极性分析

文件列表(压缩包大小 5.18M)
免费
概述
基于新浪微博数据的情感极性分析,使用机器学习算法训练模型,使用的分类方法包括朴素贝叶斯、SVM。
用法
'''
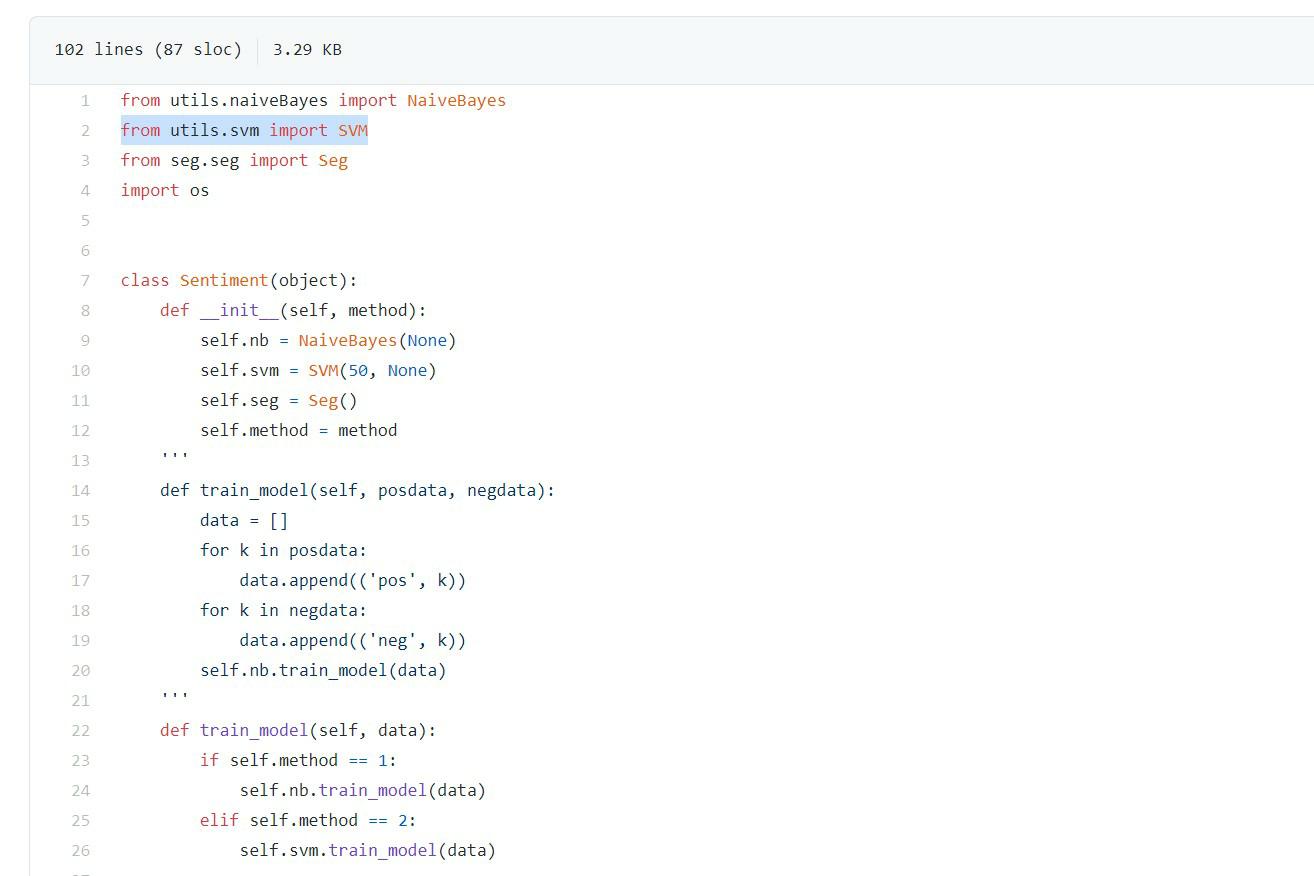
初始化: SimpleNLP(method, doc, datalist)
参数说明: method - 使用的分类方法 - 数字: 1 = Naive Bayes, 2 = SVM
doc - 输入的文本 - 文本: None = 不使用文本
datalist - 输入的语句列表 - 列表: None = 不使用语句列表
'''
doc = ```杰森我爱你!加油你是最棒的!```
datalist = ['来自东方的神秘力量', '无聊']
nlp = SimpleNLP(1, doc, datalist)
# 分词
seg_doc = nlp.seg_doc()
seg_datalist = nlp.seg_datalist()
print('分词-doc: ' + seg_doc)
print('分词-datalist: ' + seg_datalist)
# 统计词频
word_frequency = npl.get_keyword_datalist()
print('词频: ' + word_frequency)
# 情感分析
sentiment_doc = nlp.sentiment_analysis_doc()
sentiment_datalist = nlp.sentiment_analysis_datalist()
print('情感分析-doc: ' + sentiment_doc)
print('情感分析-datalist: ' + sentiment_datalist)
# 结果
分词-doc: [['杰森', '加油', '棒', '我爱你']]
分词-datalist: [['神秘', '东方', '力量'], ['无聊']]
词频: {'神秘': 1, '东方': 1, '力量': 1, '无聊': 1}
情感分析-doc: 0.9995647915879173
情感分析-datalist: [0.9993912569032992, 0.09090909090909094]
实现功能
- 分词(使用jieba分词库)
- 词频统计
- 情感分析
- 朴素贝叶斯(使用朴素贝叶斯算法训练模型)
- 支持向量机(使用了sklearn工具)
- 特征值提取(使用卡方检验算法)
详细说明
(1)特征值提取 对应文件: feature_extraction.py
主要作用:
- 输入文本和对应的标签值
- 使用卡方检验计算每个关键词的相关性
- 根据需要输出有效关键词列表
核心算法: 卡方检验,排名越高代表特征相关度越高
举例: 考察特征词"喜欢"和类别"positive"的相关性
| 特征选择 | 属于"positive" | 不属于"positive" | 总计 |
|---|---|---|---|
| 包含"喜欢" | A | B | A + B |
| 不包含"喜欢" | C | D | C + D |
| 总数 | A + C | B + D | N |
则卡方("喜欢", "positive") = N(AD - BC)^2 / (A+C)(B+D)(A+D)(B+C)
(2)支持向量机 对应文件: svm.py
主要作用:
- 输入惩罚系数C、关键词列表和训练数据
- 根据训练数据,构建词向量
- 根据词向量和训练集标签,利用sklearn工具进行拟合
- 输入测试词列表,预测分类
核心算法: 词向量构建、支持向量机
(3)朴素贝叶斯 对应文件: naiveBayes.py
主要作用:
- 输入训练数据集、关键词列表
- 构建分类模型
- 输入测试词列表,利用朴素贝叶斯算法计算各类别概率
核心算法: 朴素贝叶斯
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







