 资源下载
资源下载


【毕业设计】基于半监督学习和集成学习的情感分析研究

文件列表(压缩包大小 19.52M)
免费
概述
基于半监督学习和集成学习的情感分析研究
数据
text/JDMilk.arff[tf-idf]
对于baseline 7%作为训练集 30%作为测试集
对于SSL alg 7%作为训练集 63%无标注数据集 30%作为测试集
参考:[高伟女硕士]基于随机子空间自训练的半监督情感分类方法
切分训集和测试集 四折交叉验证 具体做法是:将数据集分成四份,轮流将其中3份作为训练数据,1份作为测试数据,进行试验,最终采用10次结果的正确率的平均值作为对算法精度的估计 显然,这种估计精度的做法具有高时间复杂度
测试标准
准确率(Accuracy)
环境配置
python2.7 scikit,numpy,scipy docker
算法
监督学习(SL)的分类器选择
选择标准:能够输出后验概率的
1.支持向量机(SVC)
2.朴素贝叶斯-多项式分布假设(MultinomialNB)
半监督学习(SSL)
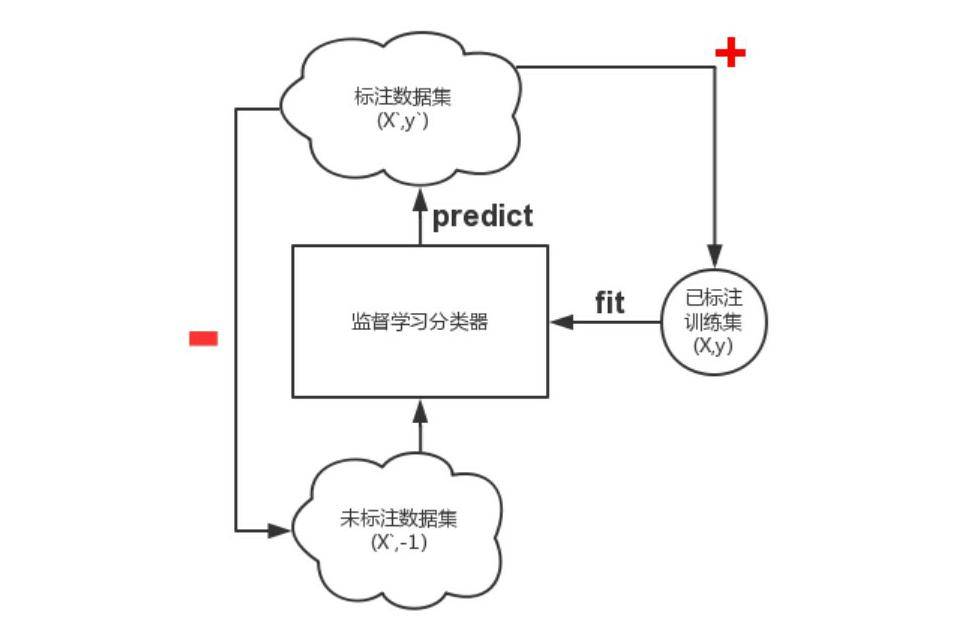
1.Self-Training 最原始的半监督学习算法,但是容易学坏,压根没有改善,甚至更差 Assumption:One's own high confidence predictions are correct.
其主要思路是首先利用小规模的标注样本训练出一个分类器,然后对未标注样本进行分类,挑选置信度(后验概率)最高的样本进行自动标注并且更新标注集,迭代式地反复训练分类器
2.Co-Training 特点:Original(Blum & Mitshell)是针对多视图数据(网页文本和超链接),从不同视图(角度)思考问题,基于分歧
Original视图为2,分别是网站文本和超链接 p=1,n=3,k=30,u=75 Rule#1:样本可以由两个或多个冗余的条件独立视图表示 Rule#2:每个视图都能从训练样本中得到一个强分类器
视图数量4比较好[来自苏艳文献],每个视图内包含的特征数量m为:总特征数量n/2[来自王娇文献]。但是,普通情感评论文本(nlp)并没有天然存在的多个视图,考虑到情感文本中特征数量非常庞大,利用随机特征子空间生成的方式
[RandomSubspaceMethod,RSM]将文本特征空间分为多个部分作为多个视图 但是视图之间至少得满足'redundant but notcompletely correlated'的条件
因为多个视图之间应该相互独立的,如果都是全相关,那么基于多视图训练出来的分类器对相同待标记示例的标记是完全一样的,这样一来Co-Training 算法就退化成了 self-training 算法[来自高原硕士文献]
Ramdom Subspaces
最早来源于Tin Kam Ho的The Random Subspace Method forConstructing Decision Forests论文,for improving weak classifiers.
①来自王娇博士文献叙述 假设原数据特征空间为n维 ,随机子空间为 m 维 ,满足 m < n.设标记数据集有l个数据,即| L| = l. 对任意 p ∈ L ,可写成 p = (p1 , p2 , …, pn),将p投影到这m维张成的空间中 ,得到的向量可写成 psub = ( ps1 , ps2 , …, psm)由所有 l 个 psub组成的向量集合Lsub ,就是标记数据集L在其 m维随机子空间中的投影. 重复此过程 K次 ,得到数据特征空间的 K个不同视图,Lsubk(1 ≤k ≤K) Q:还是没有说清楚投影(切分)和随机这两者怎么实现?
②from wikipedia: 1.Let the number of training points be N and the number of features in the training data be D. 2.Choose L to be the number of individual models in the ensemble. 3.For each individual model l, choose dl (dl < D) to be the number of input variables for l. It is common to have only one value of dl for all the individual models. 4.For each individual model l, create a training set by choosing dl features from D with replacement and train the model.
③出处Tin Kam Ho的The Random Subspace Method forConstructing Decision Forests
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







