资源下载
资源下载

0
我们将从了解k-NN和k-means聚类的工作原理开始。
K最近邻算法(K-NN)
k-NN是用于分类的监督算法。这意味着我们有一些预先标记的数据,我们将其提供给模型以使其了解该数据(即训练)中的动态。然后,它利用这些学习对测试数据进行推断。在分类的情况下,标记的数据实际上是离散的。
 步骤:
1.确定相似性或距离指标。
步骤:
1.确定相似性或距离指标。
2.将原始标记的数据集拆分为训练和测试数据。
3.选择一个评估指标。
4.确定k的值。这里k表示在对目标标签进行多数投票时我们将考虑的最邻近的数量。
5.多次运行k-NN,更改k并检查评估指标。
6.在每次迭代中,k邻近值投票,多数票获胜并成为最终预测的值。
7.通过选择评估效果最佳的k来优化k。
8.选择k后,使用相同的训练集,然后创建一个新的测试集,其中包含没有标签的并且想要预测的人们的年龄和收入。
k均值
k-Means是用于聚类的无监督算法。所谓无监督,是指我们没有任何预先标记的数据来训练模型。因此,该算法仅依靠独立特征的动态来推断看不见的数据。
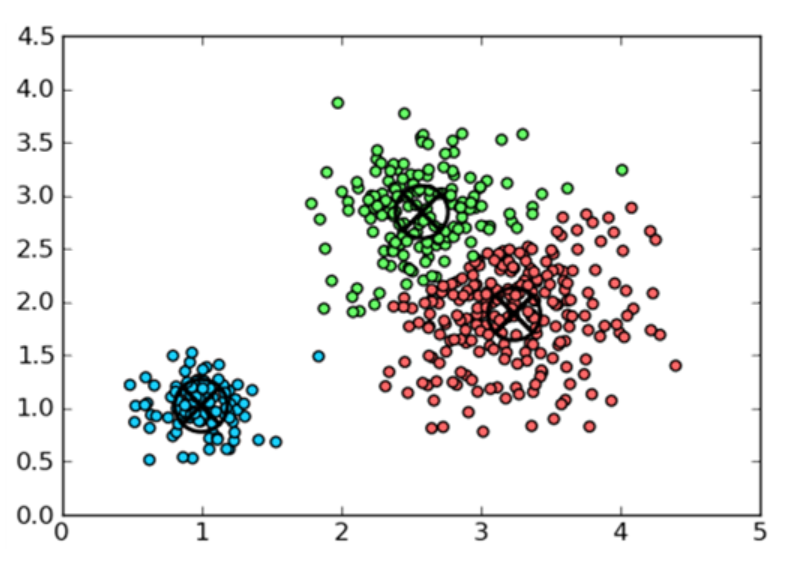 步骤
1.最初,随机选择k个质心/聚类中心。尝试使它们靠近数据但彼此不同。
步骤
1.最初,随机选择k个质心/聚类中心。尝试使它们靠近数据但彼此不同。
2.然后将每个数据点分配给最接近的质心。
3.将质心移动到分配给它的数据点的平均位置。
4.重复前面的两个步骤,直到分配不变或变化很小。
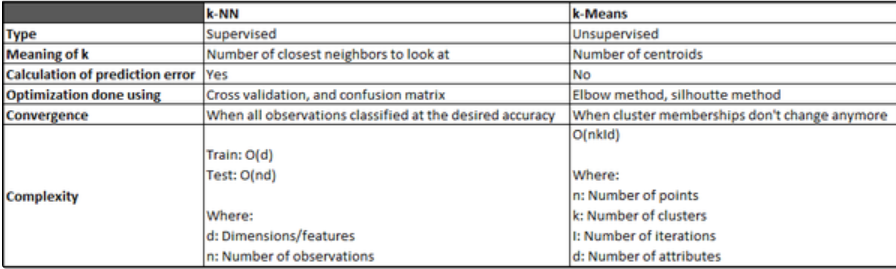
比较两种算法
收藏