 资源下载
资源下载

百度有一个贝叶斯技术体系的框架,主要分三大类:第一类是主题模型,这个框架的特点就是它有一个自配置的功能;第二类是点击模型,主要是应用在搜索引擎的领域,来量化分析用户的搜索行为以及搜索查询和网页的相关性;第三类是分类模型,包含最常见的基于贝叶斯网的分类器。
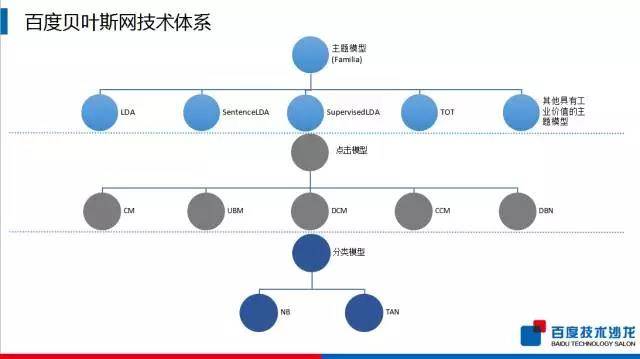
主题模型框架中有十几个主流的主题模型,其中包含 LDA 模型、引入了句子结构的 SentenceLDA 模型、引入了监督信号的 SupervisedLDA,以及其他具有工业价值的主题模型,并且支持用户根据具体任务设计对应的模型。
那么,为什么要设计 Familia 这个主题框架?业界大部分主题模型工具只支持 PLSA 和 LDA 两种模型,这两种模型非常类似,它们只支持一种数据假设,也就是说,我们只能用一种模型来适用不同的场景,不能支持用户的根据具体任务自定义扩展。
当用户的数据本身和这两个模型的假设有较大差异时,效果可想而知。另一方面,当前的主题模型工具对下游的应用并不太友好,这些工作往往只注重模型的训练,忽略了模型如何在具体任务中应用。从模型的训练到应用之间有很长的距离,如何消除这个距离是我们这个工作的重点。
Familia 在百度的应用场景其实非常多,包含了大家耳熟能详的百度搜索、百度新闻、糯米、贴吧这些平台,也部署到了百度自然语言的云处理平台上,这个工具目前每天有 3000 万次的响应需求。
Familia 框架是怎么在工业界场景进行应用的?
第一步,数据预处理,这里可以支持多种类型的数据,包括常见的网页数据、新闻数据和糯米数据,在内部将数据预处理步骤和百度的分词进行了一个深度的融合。在分词的前和后我们还有多种多样的过滤器,用户可以根据自己的需求,来选择什么信息要过滤掉,什么信息可以保留。
第二步,概率图模型配置,Familia 支持多种主流的已有的主题模型,同时用户也可以自定义自己的主题模型。这个过程是通过一种数据组织抽象存储多种图模型的信息来实现的。
第三步,采样公式自动推导,Familia 中的参数推导引擎可以自动推导出采样公式,降低了主题模型应用的数学门槛。
第四步,模型的后期处理,Familia 进一步对训练好的主题模型进行优化和压缩操作。
第五步,Familia 抽象了语义表示和语义匹配两个应用范式,用户可以根据具体任务来使用对应的范式。







