资源下载
资源下载

在各个 NLP 开放接口之中,语义计算是一个非常基础的技术。百度 NLP 部门的主任架构师孙宇主要围绕 NLP 语义计算整体技术框架展开分析,核心介绍了语义表示技术和语义匹配技术。
百度 NLP 语义计算整体框架主要分三大部分(如下图),最底层依托于大数据、网页数据和用户行为数据,以及高性能集群(GPU、CPU 和 FPGA),打造了基于 DNN 和概率图模型的语义计算引擎,通过文本输入到语义计算引擎当中,可以得到文本的语义表示,进而基于这个语义表示,进行语义层面的计算,包括语义匹配、语义检索、文本分类、序列生成以及序列标注。
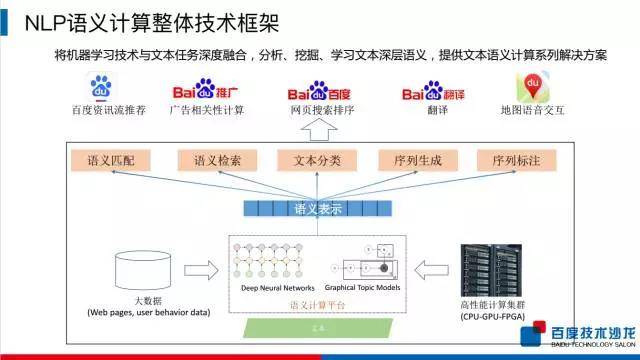
目前,百度在语义方面开放了四个技术,囊括了词汇和句子两个层面的语义技术。词汇层面包括了词语义向量表示,词义相似度计算;句子层面的包括短文本语义相似度计算和 DNN 语言模型。孙宇对这些技术背后的原理进行了详细的介绍。
语义表示技术业界很早就开始研究,主要有两种流派,一个是形式化的方法,一个是基于统计的方法。
关于基于形式化的方法,在上世纪八十年代普林斯顿有科学家提出:基于语言学知识构建一个词图,把知识通过词与词之间的关系构建到这个图里。
九十年代又有人提出,将自然语言表示成一种逻辑的表达式,可以直接用于计算机计算和执行。但这两个技术都存在一个问题:自动化程度不高,适用性较差,因此,百度 NLP 主要采用基于统计的方法。
短文本语义相似度计算是他们重点打造、应用广泛的技术。其中的核心模型是利用他们 2013 年开始研发的 SimNet 语义匹配框架,在千亿级别真实点击数据训练得到。该框架的基础匹配算法上包含两种匹配范式,一种侧重于表示层建模,另外一种则更侧重于匹配层建模。
这两种模型各有优势,可解决不同问题。另外,针对不同应用场景他们还扩展研发了基于字符级别匹配和多视角匹配技术,这些技术都广泛应用于百度内部各产品中。