 资源下载
资源下载



【毕业设计】基于Django和vue的微博用户情感分析系统

文件列表(压缩包大小 16.89M)
免费
概述
这里简单说明一下项目下下来直接跑起的方法。前提先搞好python环境和vue环境,保证你有一个账户密码连上数据库mysql。 1、pip install requirements.txt 安装python包 2、修改mysql数据库的账户密码(weibosystem/ssettings)里面 3、创建数据库 python manage.py makemigrations python manage.py migrate 4、创建后台xadmin账户python manage.py createsuperuser 5、登录后台,http://localhost:8000/xadmin/SpiderAPI/target/ 在爬虫API里面的爬虫设置,输入一个用户uid + cookie,然后即可开始在首页localhost:8000数据爬虫id爬虫
系统介绍 extra_apps:xadmin后台管理系统
scrapydserver:Scrapy爬虫
src:django app里面写接口
webview:前端Vue代码
weibosystem:django wsgi/url等配置
前端使用:vue-cli + vue + vuex + axios
后端使用:python + django + xadmin + request + scrapy + scrapyd + snownlp(模型已训练好,但并不是特别准确)
系统功能介绍 ① 输入微博oid,爬取个人微博信息,情感分析处理后并展示(oid获取方式,进入个人微博首页如: https://weibo.com/u/1797112632 ,其中1797112632就是oid。)有些用户自定义了域名,右击查看网页源代码,搜索['oid']即可找到oid。下图是本系统爬取个人信息界面:


② 输入单条微博id,爬取个人微博信息(获取单条微博id的方式,打开微博客户端,随便找到一条微博,进入微博正文,点击右上角三个点,然后可以看到分享给微信好友,QQ好友等,在下面一栏有收藏等,往右边拖,找到复制链接,复制并粘贴出来。如 https://m.weibo.cn/1769965211/4366947749433348 ,其中4366947749433348就是单条微博id。)情感分析处理后并展示。本系统展示单条微博例子如下:
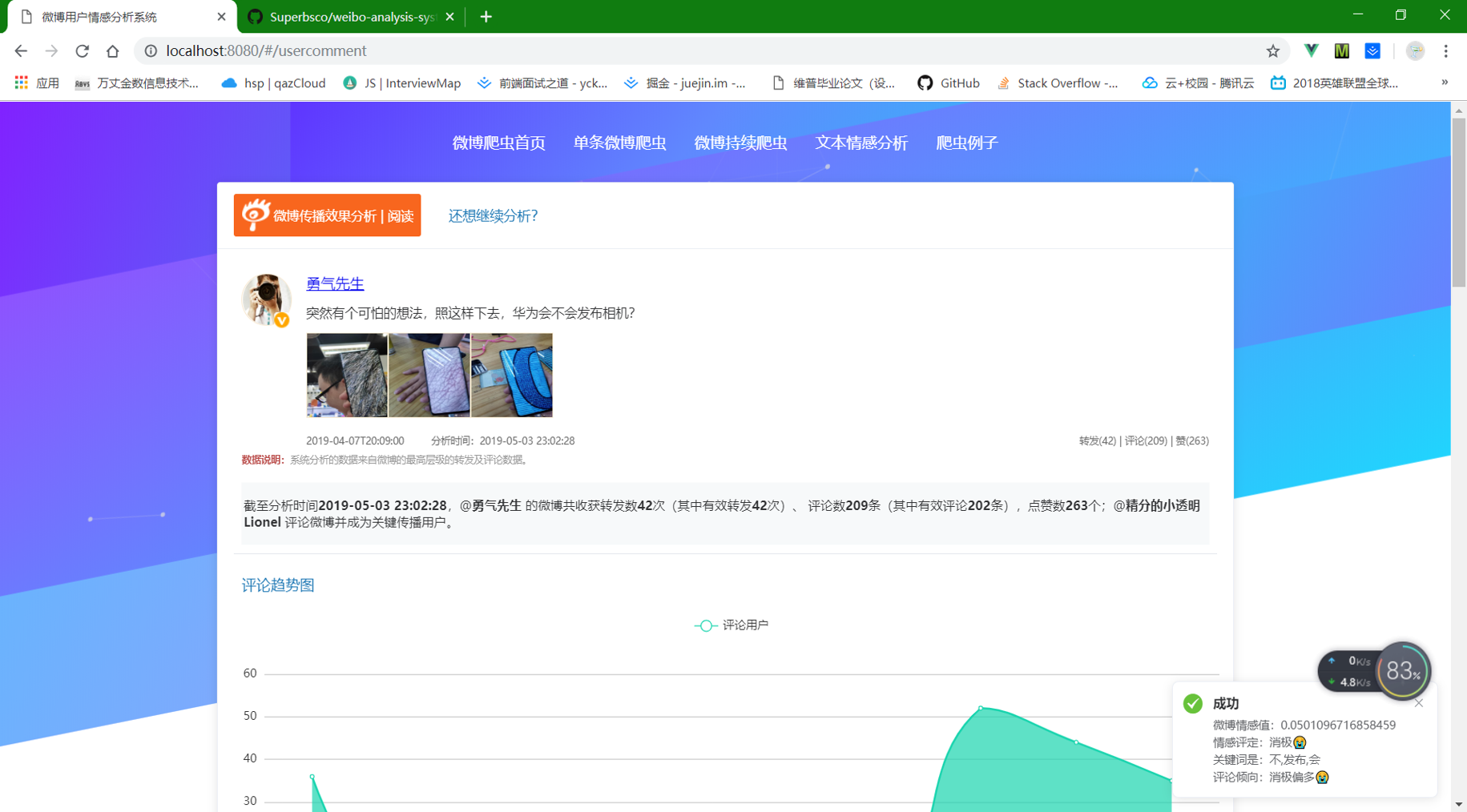
③ 输入微博id,或者多个微博id和Cookie启动持续爬虫。前提先运行Scrapyd服务。这个功能使用Scrpay爬虫,然后把数据存到Django的Model中。
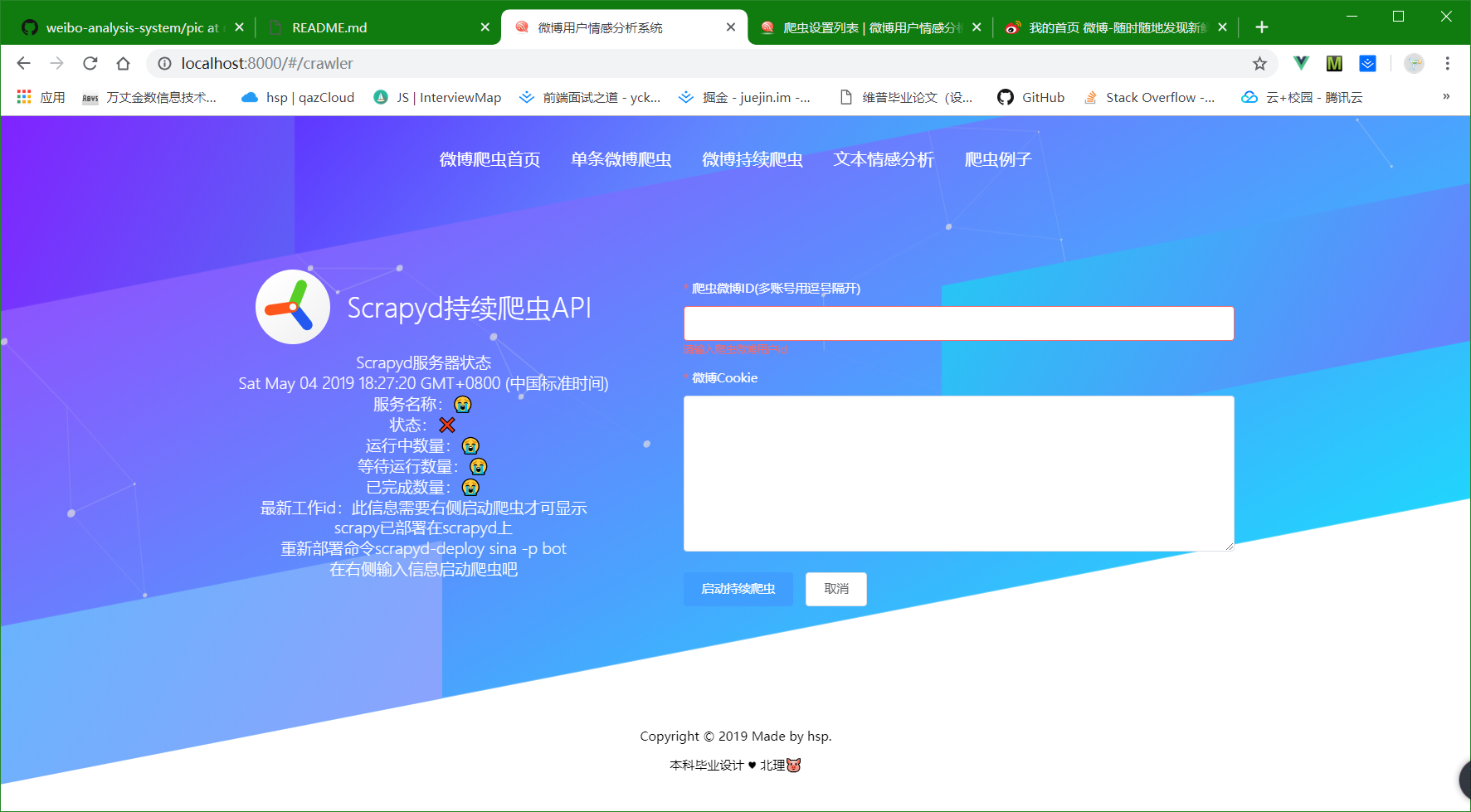
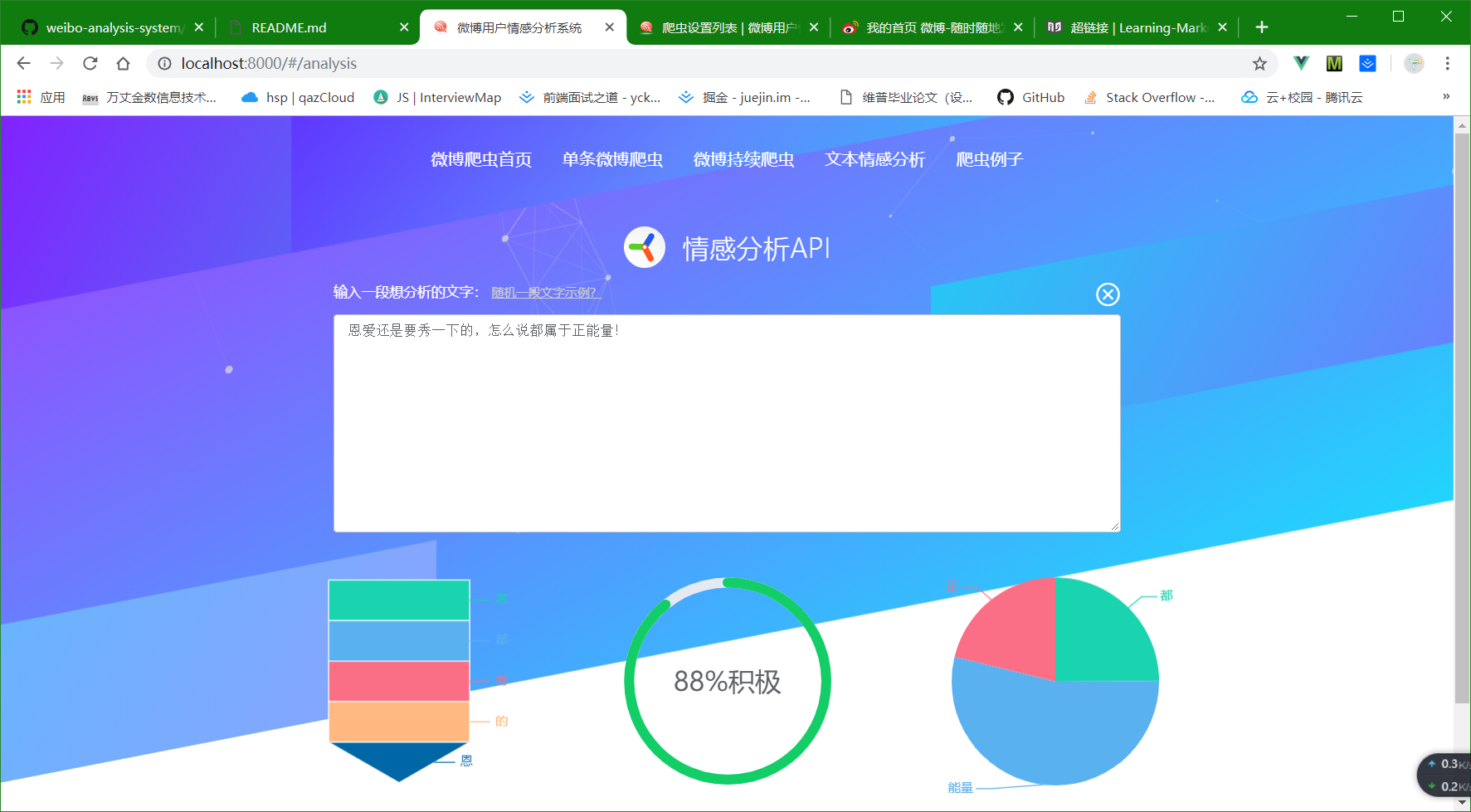
④ 独立出来的文本情感分析API,输入任意一段中文,返回情感分析值,词频,关键词。
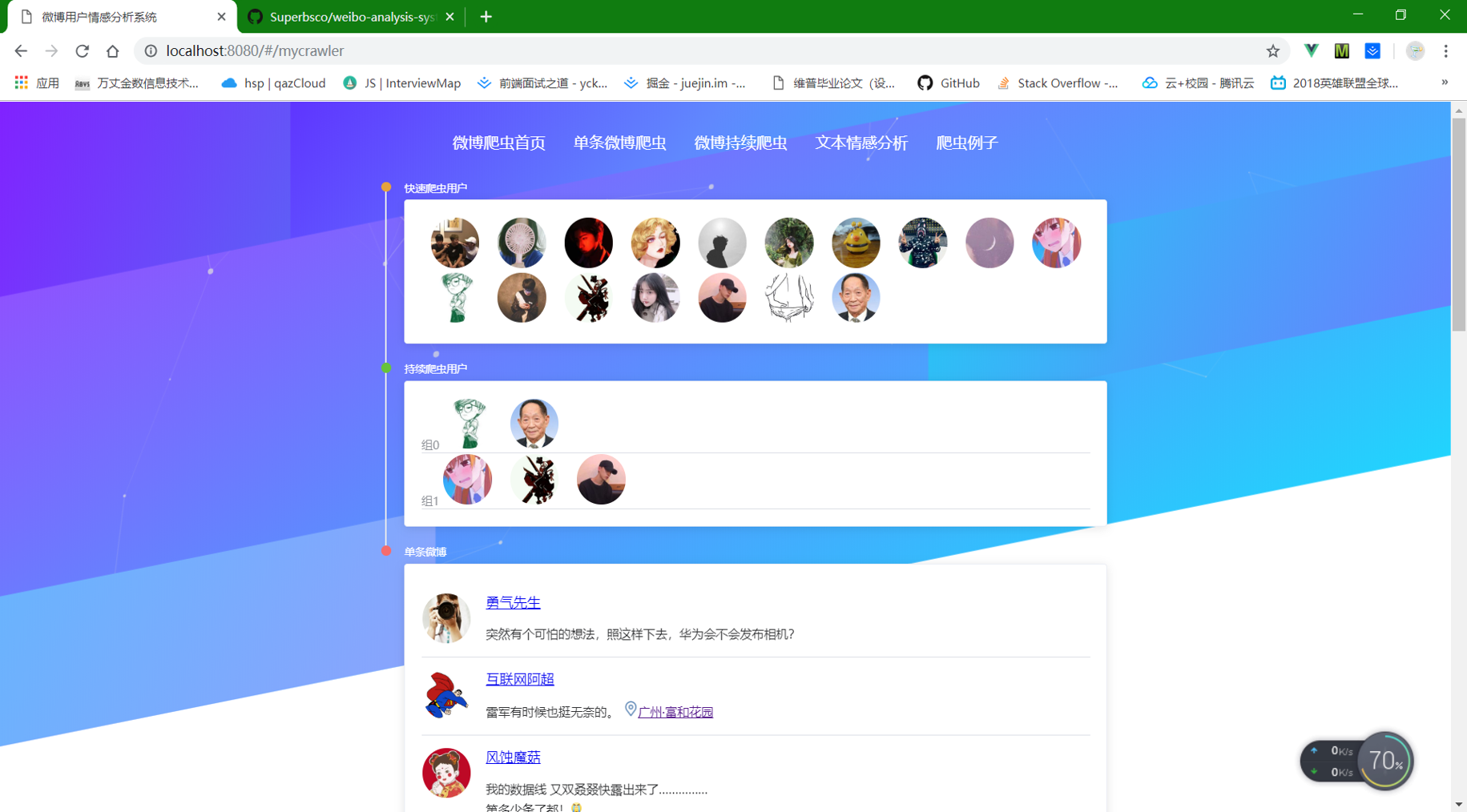
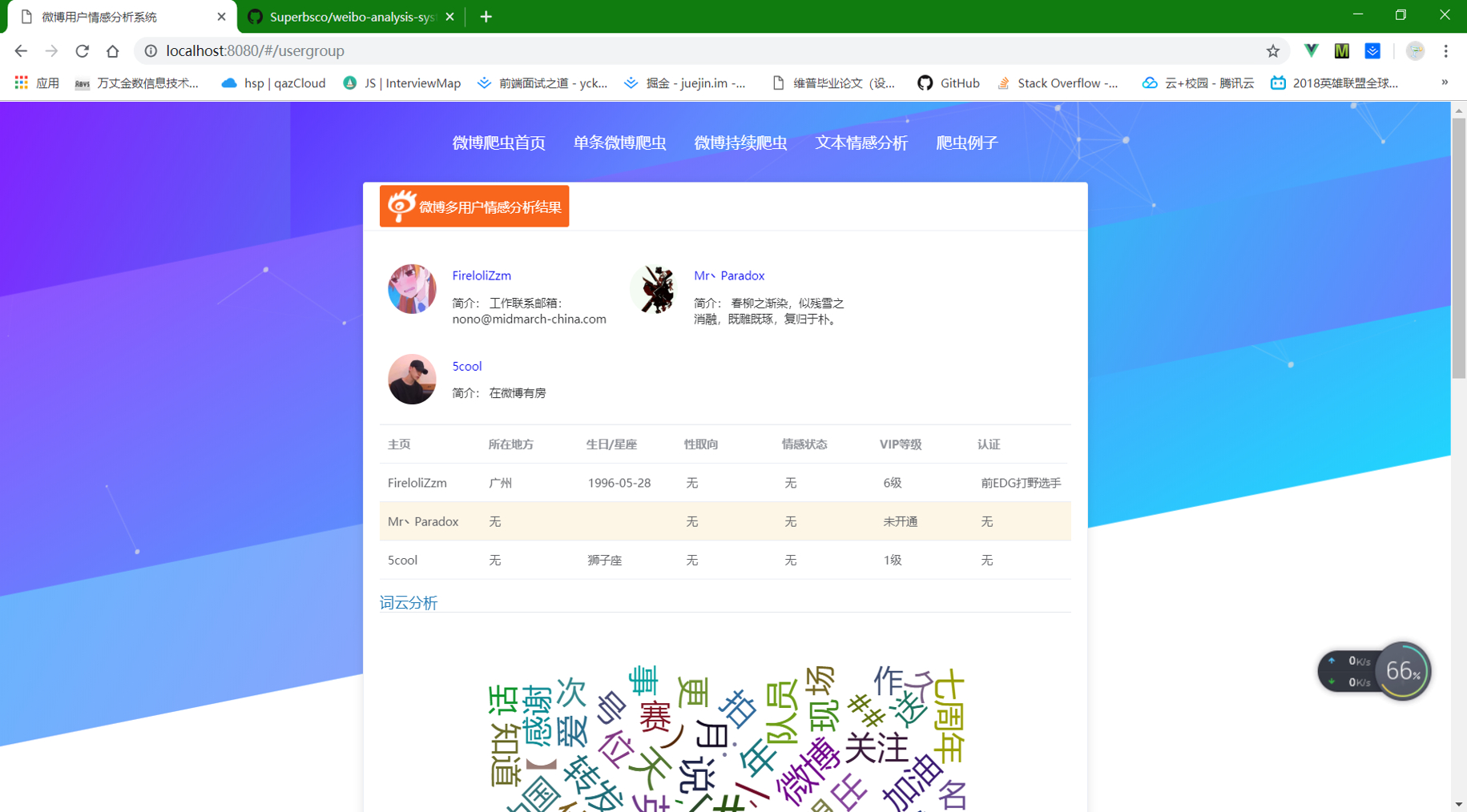
⑤ 数据库已爬虫的用户,其中持续爬虫模块点击进去就是③中的多用户爬虫,默认设置了组别是1,如需修改进入xadmin后台,修改即可,上面的点击个人账号,点击单条微博,也是进入信息展示界面。点击组别进入的多用户爬虫界面如下图:
⑥ xadmin后台管理系统

系统启动注意事项
按照技术文档操作完了之后,workon进入虚拟环境:
1、数据库自动生成,使用如下命令: python manage.py makemigrations python manage.py migrate 2、初始化Cookies 爬虫之前一定要先进入xadmin后台,使用数据库自动生成后,xadmin的登录账号密码就没了,参考这里初始化账号:https://blog.csdn.net/a_little_snail/article/details/76984933 , 然后重设Cookie,获取新浪微博Cookie,可参考 https://blog.csdn.net/A_xiao_mili/article/details/77947802 这里。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







