 资源下载
资源下载

基于Flume,Kafka,SparkSql模拟的实时日志分析系统

文件列表(压缩包大小 4.62M)
免费
概述
NetWordCount是基于socket、SparkStreaming模拟的实时日志分析系统
程序说明
mySQL表结的代码
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `pv`;
CREATE TABLE `pv` (
`page` char(200) NOT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`page`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `ip`;
CREATE TABLE `ip` (
`ip` char(20) NOT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`ip`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `explorer`;
CREATE TABLE `explorer` (
`explorer` char(20) NOT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`explorer`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `area`;
CREATE TABLE `area` (
`area` char(100) NOT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`area`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
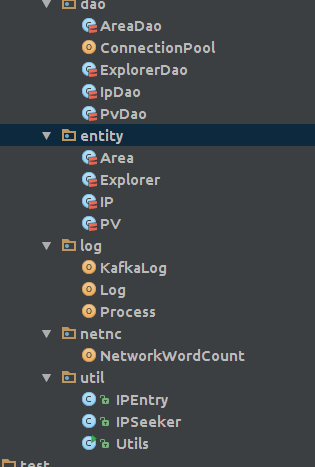
程序结构
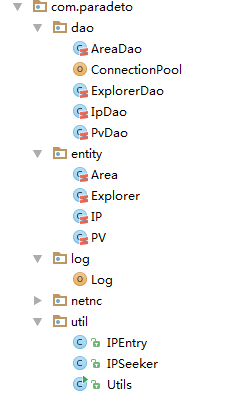
- dao:mysq数据库操作类
- entity:实体类,分别对应数据库中4个表
- log:统计分析,程序入口
- util:ip转地址的工具,如何使用可以参考:http://f.dataguru.cn/thread-476384-1-1.html
运行
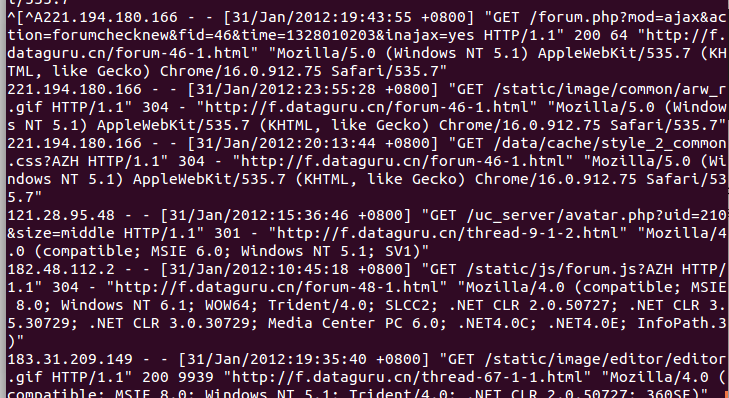
将工程下的Socket子工程打包运行,模拟日志的动态生成
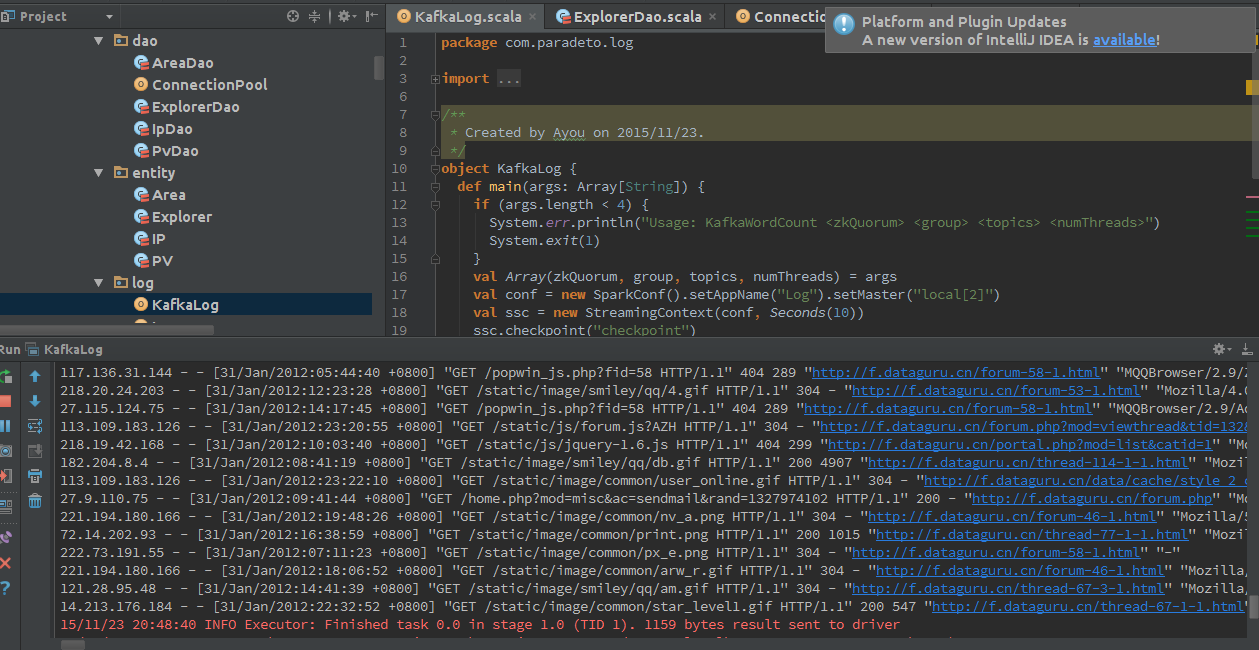
在IDEA中运行Log类的main方法
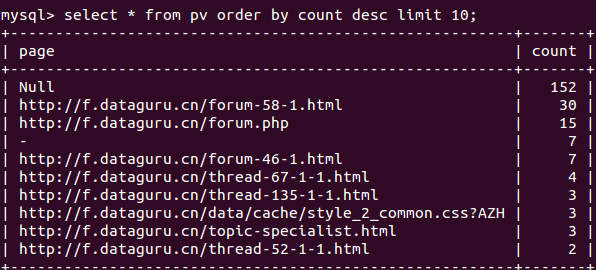
 mysql数据库的结果
mysql数据库的结果
[size=10.5000pt]IP:

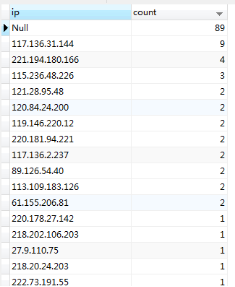
PV:
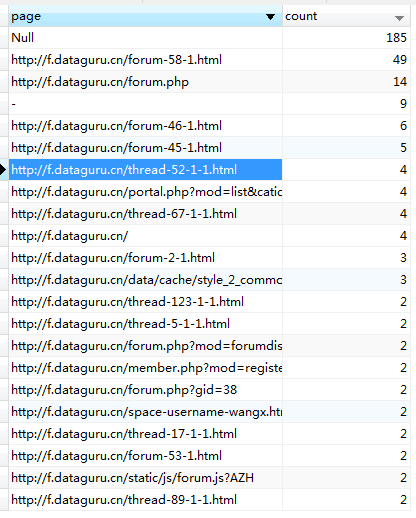
浏览器:
 详情请参考:http://f.dataguru.cn/thread-590937-1-1.html
详情请参考:http://f.dataguru.cn/thread-590937-1-1.html
KafkaMQ是基于Flume、Kafka、SparkStreaming模拟的实时日志分析系统
系统架构说明

代码说明
SimulateLog
模拟日志的动态生成,将日志写入到文本文件中。
对象SimulateLog {
def index(length:Int)= {
导入Java .util.Random
val rdm =新随机
rdm.nextInt(长度)
}
def main(args:Array [String]){
如果(args.length!= 3){
System.err.println(“用法:<文件名> <毫秒> <logFilename>”)
System.exit(1)
}
//数据来源
val文件名= args(0)
val行= Source.fromFile(文件名).getLines.toList
val filerow = lines.length
//写日志
新线程() {
覆盖def运行= {
val out =新的PrintWriter(args(2),“ UTF-8”)
而(true){
Thread.sleep(args(1).toLong)
val内容=行数(index(filerow))
println(内容)
out.write(内容+'\ n')
out.flush()
}
out.close()
}
}。开始()
}
}
KafkaSink
自定义的flume sink,将flume收集的日志发送到kafka broker
public class KafkaSink extends AbstractSink implements Configurable {
private static final Log logger = LogFactory.getLog(KafkaSink.class);
private String topic;
private Producer producer;
public void configure(Context context) {
// 这里写死了,不太好
topic = "kafka";
Map<String,String> props = new HashMap<String,String>();
props.put("bootstrap.servers", "localhost:9092");
//props.put("serializer.class", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// props.setProperty("producer.type", "async");
// props.setProperty("batch.num.messages", "1");
//props.put("request.required.acks","1");
producer = new KafkaProducer(props);
}
public Status process() throws EventDeliveryException {
Channel channel =getChannel();
Transaction tx =channel.getTransaction();
try {
tx.begin();
Event e = channel.take();
if(e ==null) {
tx.rollback();
return Status.BACKOFF;
}
ProducerRecord data = new ProducerRecord(topic,null,new String(e.getBody()));
producer.send(data);
logger.info("Message: {}"+new String( e.getBody())); tx.commit(); return Status.READY;
}
catch(Exception e) {
logger.error("KafkaSinkException:{}",e);
tx.rollback();
return Status.BACKOFF; }
finally {
tx.close();
}
}
}
NetworkWordCount
运行说明
1.把KafkaMQ打包,运行SimulateLog,产生日志写到文本文件中,这里数据还是日志文件,跟题目要求有点不一致。
java -cp KafkaMQ.jar com.paradeto.simulatelog.SimateLog ./access_log.txt 2000 ./out.txt
 2.安装zookeeper和kafka,启动zookeeper,启动kafka,创建名为kafka的topic略
2.安装zookeeper和kafka,启动zookeeper,启动kafka,创建名为kafka的topic略
3.安装flume,将KafkaMQ.jar拷贝到flume的lib目录下,运行以下代码,实时收集日志 flume-ng agent --conf ./ --conf-file ./kafka-conf --name agentkafka -Dflume.root.logger=INFO,console
kafka-conf如下所示:
agentkafka.sources = exectail
agentkafka.channels = memoryChannel
agentkafka.sinks = kafkaSink
# For each one of the sources, the type is defined
agentkafka.sources.exectail.type = exec
agentkafka.sources.exectail.command = tail -F /home/youxingzhi/kafka/out.txt agentkafka.sources.exectail.batchSize=20
agentkafka.sources.exectail.channels = memoryChannel
agentkafka.channels.memoryChannel.type = memory
agentkafka.channels.memoryChannel.keep-alive = 10 agentkafka.channels.memoryChannel.capacity = 100000 agentkafka.channels.memoryChannel.transactionCapacity =100000 agentkafka.sinks.kafkaSink.type= com.paradeto.sink.KafkaSink agentkafka.sinks.kafkaSink.channel= memoryChannel agentkafka.sinks.kafkaSink.kafkasink.server= 127.0.0.1:9092 agentkafka.sinks.kafkaSink.kafkasink.topic= kafka
在idea中运行KafkaLog
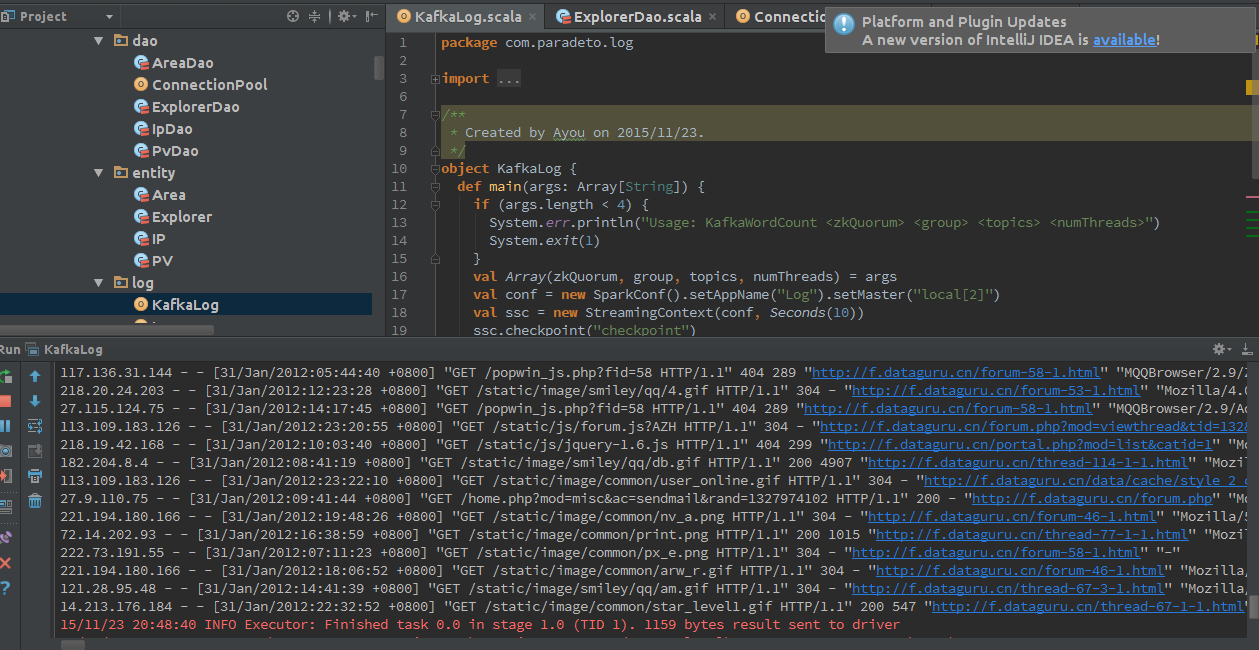 结果如下
结果如下
 详情请参考:http://f.dataguru.cn/thread-569488-1-1.html
详情请参考:http://f.dataguru.cn/thread-569488-1-1.html
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250






