资源下载
资源下载

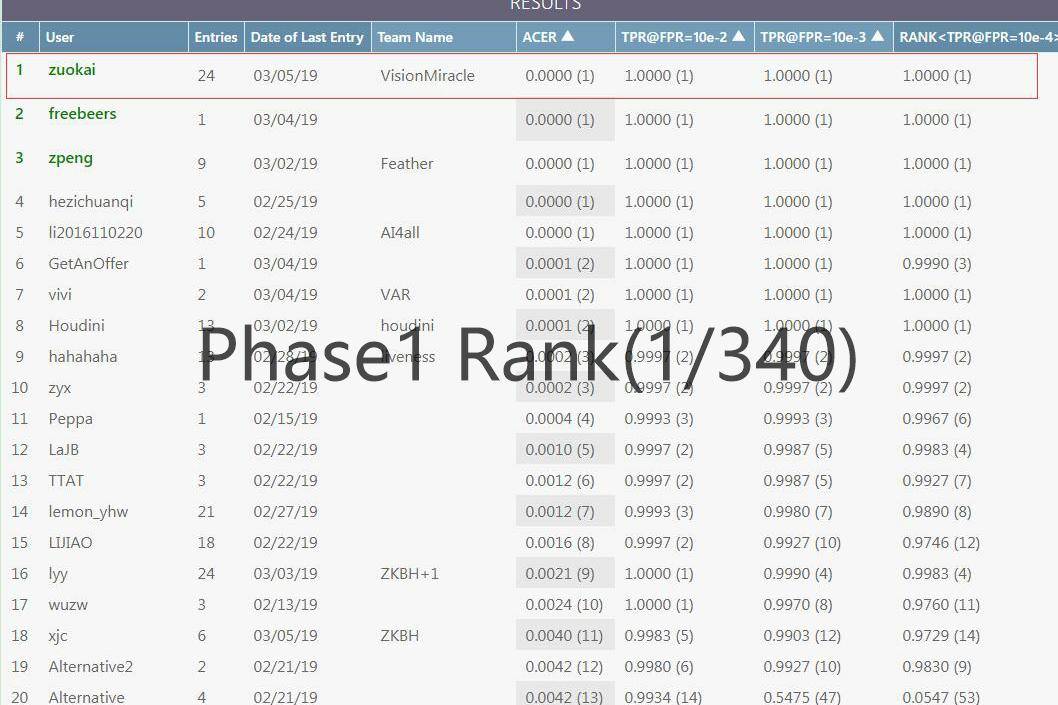
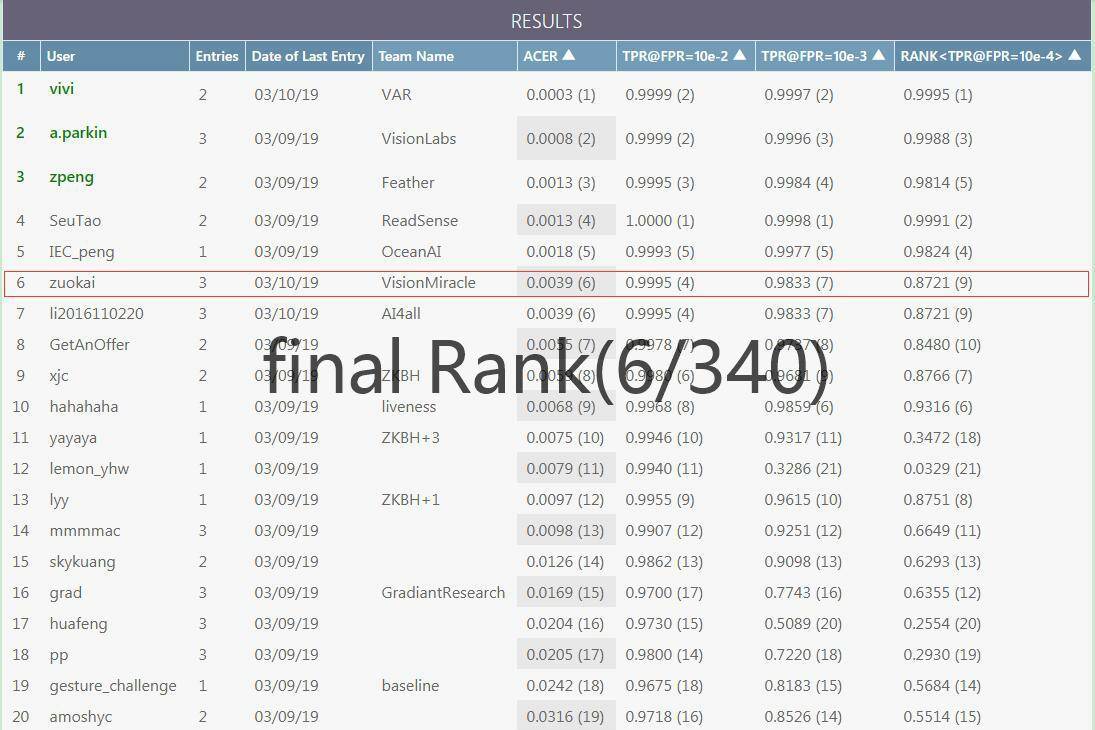
【Demo】人脸反欺骗攻击检测挑战的代码

文件列表(压缩包大小 19.26M)
免费
概述
代码和数据集存放
- 获取数据集,即CASIA-SURF文件夹,里面包含phase1和phase2两个文件夹,进入phase1,解压train.zip和valid.zip文件,得到Training文件夹,train_list.txt文件、Val文件夹、val_public_list.txt文件;
- 将本项目整个文件夹casia-surf-2019-codes拷贝到CASIA-SURF目录里面,保证和phase1同目录;
- 获得phase2阶段的测试数据集,Testing文件夹和test_public_list.txt文件放在phase2目录下;
最终目录结构如下:
./ casia-surf-2019-codes/ ... phase1/ Training/ Val/ train_list.txt val_public_list.txt phase2/ Testing/ test_public_list.txt
环境安装(ubuntu 16.04):
打开命令终端,cd到casia-surf-2019-codes目录,执行:
pip install -r requirements.txt
数据集预处理:
打开命令终端,cd到casia-surf-2019-codes目录,依次执行:
1. python data_preprocess.py (生成val数据集的val_depth_all_112_9608.lst文件)
2. python data_preprocess.py train (生成train数据集的train_depth_all_112_29266.lst文件)
注:样本总数:29266,其中正样本:8942,负样本:20324;
3. python data_preprocess.py train --no-enmfake (生成train数据集的train_depth_noenmfake_112_15460.lst文件)
注:样本总数:15460,其中正样本:8942,负样本:6518;
为了得到更均衡的正负样本分布,进行下采样,移除了负样本中5,6两种(同时扣除眼镜、鼻子、嘴巴的平面和弯折)攻击方式;
4. python data_preprocess.py train --aug (生成train数据集的train_depth_aug_112_38208.lst文件)
注:样本总数:38208,其中正样本:17884,负样本:20324;
为了得到更均衡的正负样本分布,进行上采样,直接复制所有正样本,正样本数达到原来的两倍;
5. cd data
6. python im2rec.py train_depth_all_112_29266.lst ../phase1
注:在./data目录下,生成 train_depth_all_112_29266.rec 用于mxnet训练;
7. python im2rec.py train_depth_noenmfake_112_15460.lst ../phase1
注:在./data目录下,生成 train_depth_noenmfake_112_15460.rec 用于mxnet训练;
8. python im2rec.py train_depth_aug_112_38208.lst ../phase1
注:在./data目录下,生成 train_depth_aug_112_38208.rec 用于mxnet训练;
9. python im2rec.py val_depth_all_112_9608.lst ../phase1
注:在./data目录下,生成 val_depth_all_112_9608.rec 用于mxnet验证;
模型训练
打开命令终端,cd到casia-surf-2019-codes目录:
第一步:使用29266的训练数据集进行训练,
batch_size=512,
学习率lr=1e-2,
lr_step_epochs='10'(在10个epoch后,学习率调整为1e-3),
checkpoint_period=10(每10个epoch,保存一次模型),
gpus='1,2,3'(使用第1,2,3总共3块gpu同时训练,可调整)
NOTE:
1)网络尝试了Xavier和Uniform初始化方法,Uniform均优于Xavier,因此最终选择了Uniform,如果模型精度在前5个epoch一直很低,可结束此程序,多尝试几次,保证使用较好的一个初始化权重开始学习;
2)当Validation-accuracy达到0.993左右,Validation-f1达到0.990左右时,或者精度很难进一步提升,甚至开始下降时,可以结束此阶段;
python train_depth_vmspoofnet.py
第二步:使用29266的训练数据集进行训练,
batch_size=512,
学习率lr=1e-3(可尝试1e-5,5e-6,1e-6),
lr_step_epochs='900'(设置比较大的值,用来保持固定的学习率进行训练),
checkpoint_period=1(每1个epoch,保存一次模型),
load_epoch=xxx(预加载第一步中得到的最好模型),
gpus='1,2,3'(使用第1,2,3总共3块gpu同时训练,可调整)
NOTE:
1)此阶段进行模型的微调,尝试不同的学习率,Validation-accuracy最高能达到0.997225,Validation-f1最高能达到0.995641;
python train_depth_vmspoofnet_step2.py
第三步:使用15460和38208两种样本均衡的数据集分别尝试进行微调训练,
batch_size=512,
学习率lr=1e-5(可尝试5e-6,1e-6),
lr_step_epochs='900'(设置比较大的值,用来保持固定的学习率进行训练),
checkpoint_period=1(每1个epoch,保存一次模型),
load_epoch=xxx(预加载第二步中得到的最好模型),
gpus='1,2,3'(使用第1,2,3总共3块gpu同时训练,可调整)
NOTE:
1)通过第二步得到的最好模型,发现在验证集上FN偏高,可能是由于正负样本不太均衡,导致模型更倾向于将样本预测为负例,因此第三步中,改用样本均衡后的数据集进一步微调学习,尝试了下采样和上采样两种方法,发现上采样效果好于下采样,模型精度略有提高,FN和FP也更趋于一致,说明样本均衡化改善了模型对负样本过于倾向的问题;
python train_depth_vmspoofnet_step3.py
注:1) 本人使用的是包含4块GPU的服务器,配置为:11G Memory, GeForce GTX 1080,
服务器配置:CPU:Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz 12核,64G内存,1TB固态硬盘;
测试
- 按我提供的百度网盘链接,下载训练好的模型,解压后放入casia-surf-2019-codes目录;
- 打开命令终端,cd到casia-surf-2019-codes目录,执行: 第一阶段预测:
python commit.py ../phase1/val_public_list.txt --load-epoch 73
注:
- 程序执行完后,会在当前目录下生成 commit_phase1_depth_%Y-%m-%d_server_{load-epoch}.txt 格式的结果文件
- commit.py 第一个参数为待提交成绩的list文件,第二个参数load-epoch:表示加载第load-epoch数的模型进行预测。
第二阶段预测:
python commit_phase2.py ../phase2/test_public_list.txt --load-epoch 73
注:
- 程序执行完后,会在当前目录下生成 commit_phase2_depth_%Y-%m-%d_server_{load-epoch}.txt 格式的结果文件
- commit.py 第一个参数为待提交成绩的list文件,第二个参数load-epoch:表示加载第load-epoch数的模型进行预测。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250