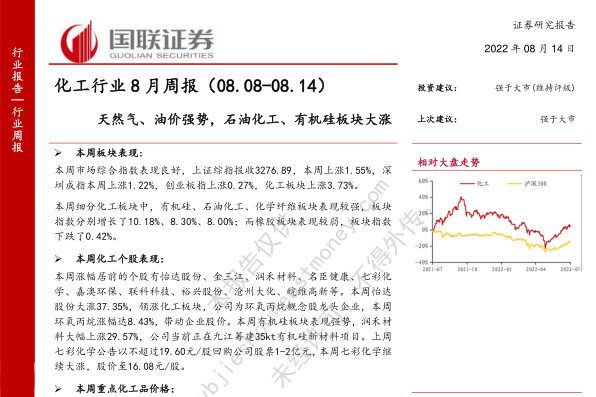
资源下载
资源下载
0
XGBoost确实令人困惑,因为超参数在不同的api中有不同的名称。不过,我要说的是,你可以对三个主要的超参数进行微调,以消除一些额外的性能。
树的数量:
命令行接口:num_round Python API: num_boost_round Scikit-learn API: n_estimators R包:nrounds
学习率:
命令行接口:eta Python API: learning_rates(一个列表) Scikit-learn API: learning_rate
树的最大深度:
命令行接口:max_depth Python API:不确定如何调优 Scikit-learn API: max_depth R包:max_depth
这些超参数基本上控制了模型的复杂性,这意味着它们与偏差和方差有关。
你的主要目标应该是尽可能地降低复杂性,同时在验证过程中保留大部分性能。这意味着在不破坏模型的前提下,你可以得到最少的树和最小的深度。
随着时间的推移,你会发现,越简单的模型就越能防止过度拟合。你越减少树的数量,就越应该提高学习速率,以确保算法收敛。
一些api还支持回调和提早停止,它们作为防止过拟合的另一种措施。如果你真的担心过拟合,也可以引入一些正规化。根据我的经验,这是很少必要的。
收藏