资源下载
资源下载

基于LSTM的股票数据分析

文件列表(压缩包大小 10.08K)
免费
概述
准备数据
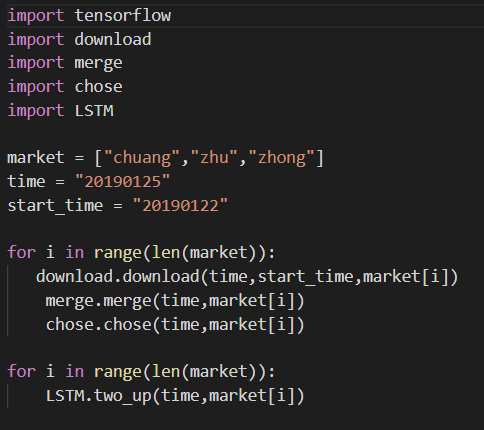
使用的是Tushare(Tushare金融大数据社区)的股票数据。主要使用其中的两项数据功能,每只股的“日线行情”和“每日指标”。把股票数据按主板、创业板、中小板分类下载共3500+只股票数据。(原则:同一只股票的数据特征相似性更高;同一板块的股票数据特征相似性更高。个股数据量太少,不太适合训练。) 代码参照download.py 对应股票、交易日期,把这两项数据合并成在一起,最原始的数据集就准备好了。 代码参照merge.py 根据个人的需求,选取想要的数据集进行训练,此为训练数据。比如:连续两天涨停的数据,作为一条训练数据;一天涨停的数据,作为一条训练数据;连续两天涨幅超过5%的数据,作为一条训练数据。(本项目的思路:1.通过N天的股票数据,预测N+1天的股票涨幅;2.不是每一个N天的股票数据,对N+1天的数据有很好的预测效果,所以需要关心的是:有很强“表现力”的N天数据,即连续涨停、连续涨幅超过5%等等;3.N天数据没有太明显表现特征,那对有明显表现特征数据来说就是噪音,噪音越多越大,对预测越不利) 代码参照chose.py
网络结构选取
选取合适的网络结构,事半功倍。在图像识别领域有很多成熟的网络结构(比如:VGG等),但是在股票领域,就需要去尝试。 1.本项目用DNN和LSTM相互做了对比,DNN对于股票数据的模型表现比较差。 2.LSTM中basicLSTMCell()单元层也可以选择不同的层数,在训练数据量足够的情况下,多层LSTM效果稍微比单层LSTM效果好,大概正确率会高1%-2%;但是LSTM不是越多越好,当LSTM层数过多时,会导致同一个batch数据的输出结果完全相同。 3.在LSTM层后面接入全连接层或者激活层,并没有给实验数据带来改观。 4.LSTM是针对时序性的数据效果表现比较突出(N个time_step),据实验:在1个time_step的情况下,LSTM的性能也比DNN表现更为突出;实验数据来自MNIST。 5.在使用LSTM时,建议把forget_bias(忘记系数)设置为0.5,能一定程度上防止overfitting。
数据反筛选
思路: 股票数据,影响其波动的因子太多,所以需要找出受相同因子影响较高的数据。 训练模型,根据模型数据,去除据偏离模型较远的个股数据。再用剩余数据训练模型,可以得到较高的拟合程度。根据本项目测试:2014年以前的个股数据,和2014年以后的个股数据,具有明显不一致特征。(具体原因不明)所以在训练数据集中,去除了2014年以前的股票数据。同时,筛选出不适合模型的个股。以上两点可以极大地提高训练模型的正确率。比如:创业板共有738只股票,去除不适合模型的378只股票,预测正确率可以达到80%-90%之间。 影响股票波动的因子太多,就不要妄想实现一个模型,可以预测整个股市。能预测其中一部分股票数据,已实属不易。
实验结果
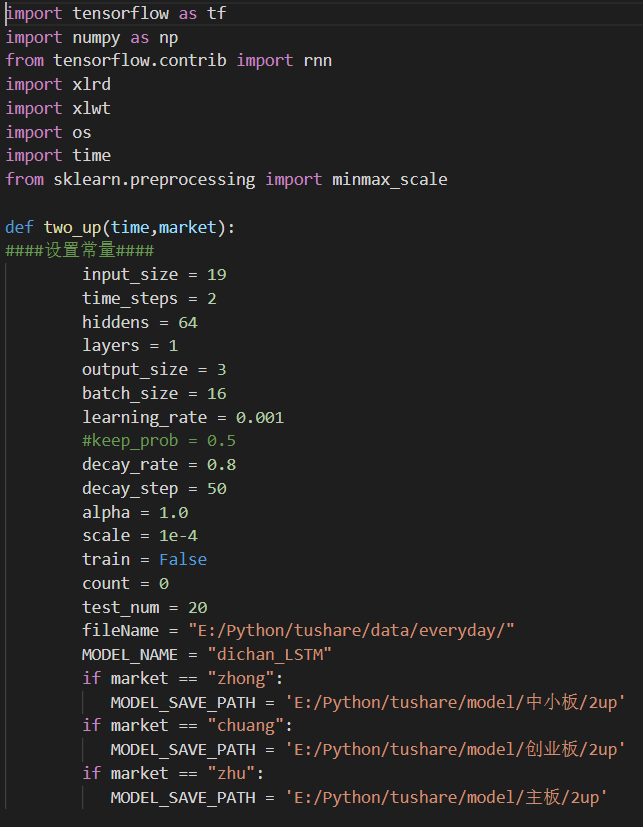
1.调参是一个比较痛苦的过程:learningrate从100-0.0000001进行了测试;batch_size从8-200进行了测试;网络层数layers从1-30层进行了测试;由于硬件环境有限,最后选取了batch_size=16,learning_rate=0.001,layers=1作为模型的超参。(只有不断调试,查看结果,才能得到想要的超参) 2.不同数据集,正确率和损失率有很大不同。在创业板300+只股票数据中,LSTM模型正确率可高达88.97%,损失率可以低至3.64%。在主板股票数据中,正确率为77.53%,损失率为7.97%。在中小板数据中,正确率为76.81%,损失率为8.63%。 正确率:预测结果正确数 / 测试数据总数 * 100% 损失率:(预测涨幅为正 and 实际涨幅为负) / 测试数据总数 * 100% 项目中遇到过的问题: 大部问题都能通过网上搜索找到解决办法: 1.在训练过程中,损失函数为几个固定值或者权重值W出现Nan(无穷大),可能是W初始化值不正确(建议不要全部初始化为“0”),也可能是训练输入数据没有标准化。 2.训练数据的时序性,一定要正确,如果时序性顺序刚好相反,会导致正确率达到100%。 另外一个问题,目前没有找到解决办法: LSTM使用过程中,不是layers层数越多越好,数据太多,会导致同一个batch数据的输出结果完全相同。上文已经说过一遍 调整网络结果和参数过程中总结的一些数据: 1.在数据量有限的DNN中,有没有dropout对实验结构影响不大。 2.优化函数: 以AdamOptimizer()为参考对象——AdamOptimizer()的优化速度值为:2;GradientDescentOptimizer()优化速度值为:0.02; MomentumOptimizer()优化速度值为:0.2;AdadeltaOptimizer()优化速度值为:0.002; RMSPropOptimizer()优化速度值为:3。
3.学习率并非越小越好,而是保证损失函数尽可能低的情况下,提高学习率,已增加学习速度。 4.在数据预测结果表现方面:2连涨停的数据特征更明显,更易得到较好的预测效果;2连涨幅超过5%的预测效果不是最好的,但是它的损失率却最低。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250