 资源下载
资源下载



【毕业设计】基于特征熵值分析的网站分类系统实现

文件列表(压缩包大小 17.72M)
免费
概述
基于特征熵值分析的网站分类系统实现
一、研究目的
本设计对KNN 算法的缺陷产生原因进行详细地分析,并针对缺陷对算法进行了引入属性熵值等一系列的改进,使得改进的 KNN 算法达到高速、高精度的性能,并且基于改进后的新 KNN 算法,搭建一个真正实用性强的网站分类系统。
二、研究方法
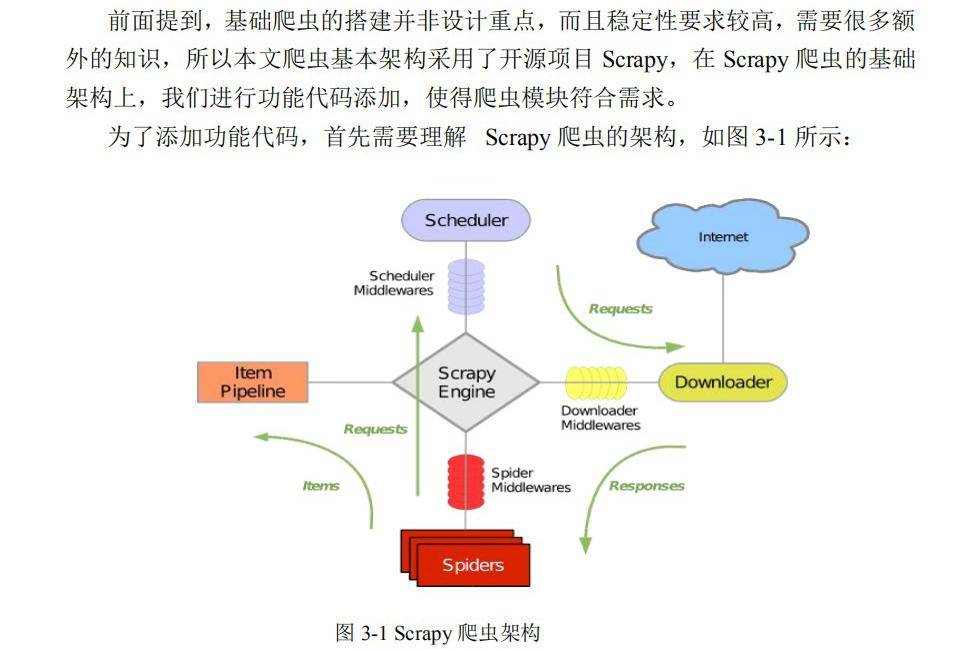
采用了语言 Python(Python 2.7.5)来对系统进行全方面设计,系统实现的平台是 Unix 操作系统。基础的爬虫搭建和页面处理涉及的分词技术均非设计重点,且稳定性要求较高, 所以这两者分别采用了目前相对稳定强大的开源工具 Scrapy 和 Jieba 分词。
三、研究结论
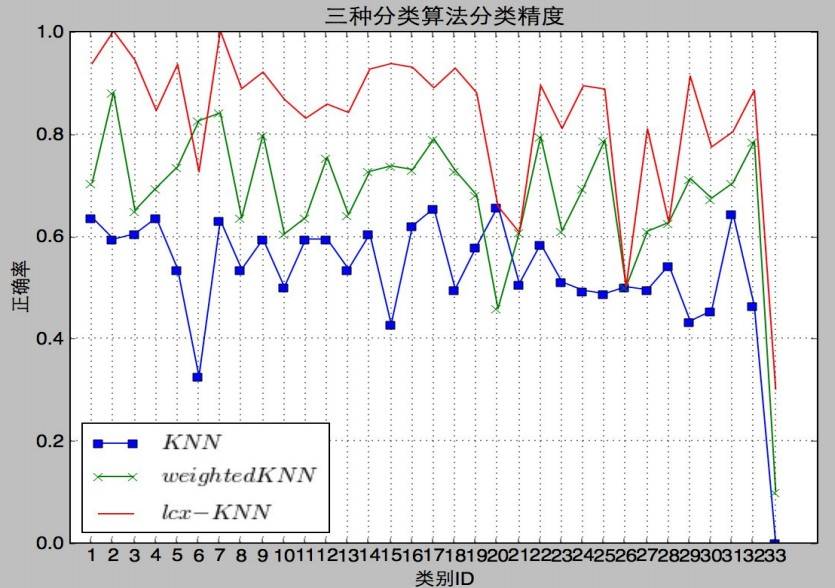
最终本系统利用个 3578 个真实网站内容作为测试集对系统进行了性能测试,最终的成绩是分类精度达到 85.05%,平均一个网页的分类速度是 0.88 秒。
四、目录
摘 要 Abstract 第 1 章 绪 论 1.1 课题的研究背景和意义 1.1.1 目前网站分类的研究情况 1.1.2 现有解决方案的优点与不足 1.1.3 基于特征熵值分析的网站分类系统的设计目标 1.2 论文的研究内容与组织结构 1.2.1 论文的研究内容 1.2.2 论文的组织结构 第 2 章 系统模块组成介绍 2.1 系统总体架构 2.2 爬虫模块功能和技术 2.3 网页处理模块功能和技术 2.4 特征提取与文本表示模块功能和技术 2.5 分类器模块功能和技术 2.6 本章小结 第 3 章 爬虫模块和页面处理模块 3.1 爬虫模块详细设计 3.2 页面处理模块详细设计 3.2.1 页面内容价值分析 3.2.2 页面处理方法 3.2.3 一种线性时间的正文提取算法 3.2.4 页面处理关键流程图 3.3 本章小结 第 4 章 特征提取与文本特征表示模块 4.1 特征提取技术介绍 4.1.1 传统的卡方检验方法(CHI) 4.1.2 传统的卡方检验方法的缺陷分析 4.1.3 一种改进的卡方检验方法 4.2 文本特征表示介绍 4.2.1 体现词在文档中权重的关键因素分析 4.2.2 TF*IDF 方法 4.3 本章小结 第 5 章 KNN 分类器模块 5.1 传统 KNN 算法介绍 5.2 传统 KNN 算法的缺陷 5.3 在运行速度上改进 KNN 算法 5.3.1 传统 KNN 算法运行速度低下的原因分析 5.3.2 用 Rocchio 算法进行预选候选类 5.3.3 根据文本的特征集与每类特征交集再次筛选候选类 5.3.4 建立倒排索引 5.3.5 引入位置向量表示法来降低高维向量计算量 5.3.6 快速 KNN 算法的系统流程 5.4 属性熵介绍 5.4.1 熵的定义 5.4.2 属性熵值的意义 5.5 在分类精度上改进 KNN 算法 5.5.1 传统 KNN 算法分类精度低的原因分析 5.5.2 引入共有特征个数改进相似度计算公式 5.5.3 引入属性熵值再次改进相似度计算公式 5.5.4 引入类别平均相似度改进在 K 邻居中各类权重公式 5.5.5 引入类别贡献度再次改进在 K 邻居中各类权重公式 5.5.6 高精度KNN算法的关键流程 5.6 本章小结 第 6 章 实验测试与评价 6.1 分类标准和训练数据 6.2 测试结果 6.3 本章小结 结 论 参考文献 哈尔滨工业大学本科毕业设计(论文)原创性声明 致 谢
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







