 资源下载
资源下载



使用 Keras 和 tensorflow 实现的Transformer模型

文件列表(压缩包大小 1.40M)
免费
概述
介绍
使用 keras+tensorflow 实现论文"Attention Is All You Need"中的模型Transformer。
数据预处理
examples/data_process.py
这将会把原始分离的英语句子和德语句子进行组装,生成下面的文件:
- data/en2de.s2s.txt
- data/en2de.s2s.valid.txt
数据来源:WMT'16 Multimodal Translation: Multi30k (de-en) (http://www.statmt.org/wmt16/multimodal-task.html).
生成字典
examples/tokenizer_test.py 这会生成以下的字典文件:
- data/dict_en.json
- data/dict_de.json 注意:默认生成的字典过滤掉了词频数小于5的词语,你可以进行修改。
训练
examples/train_test.py 训练参数和配置可在文件 train_test.py 中找到, 默认模型配置如下:
{
"src_vocab_size": 3321,
"tgt_vocab_size": 3638,
"model_dim": 512,
"src_max_len": 70,
"tgt_max_len": 70,
"num_layers": 2,
"num_heads": 8,
"ffn_dim": 512,
"dropout": 0.1
}
解码/翻译
可以使用以下方式进行解码: 1.beam_search_text_decode 2.decode_text_fast 3.decode_text 详情见: examples/decode_test.py.
效果
训练效果
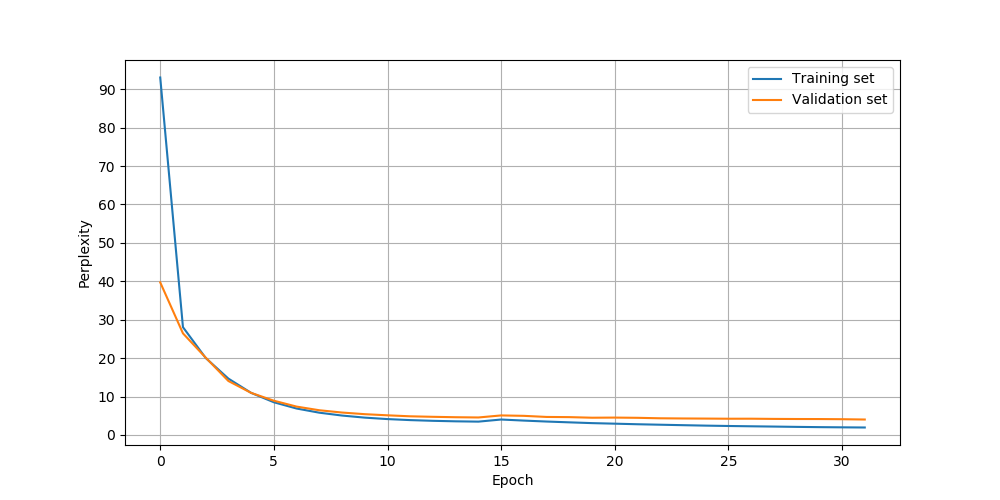
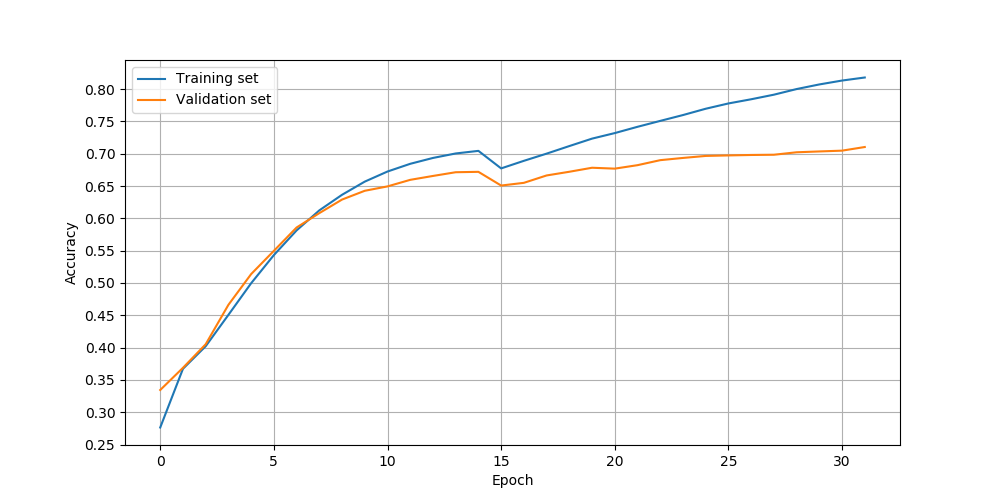
以下为使用SGDR作为学习率变化策略,迭代32次的训练效果图:
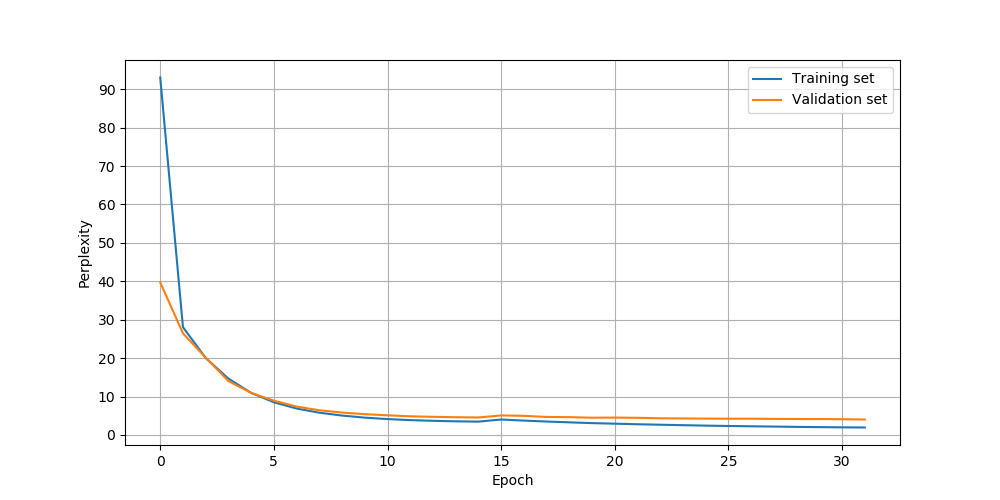
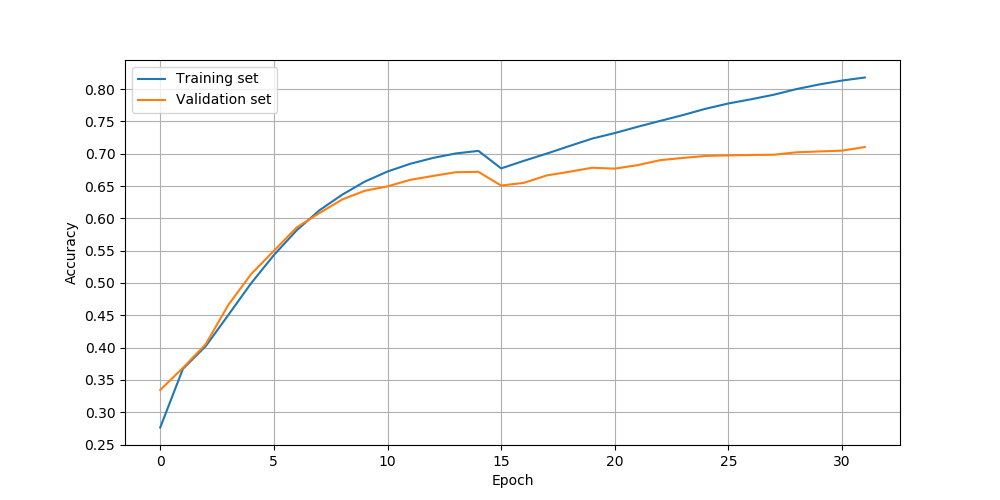 可以发现迭代30次后,验证集精度达到了70%,由于数据集很小,通过缩小模型规模,应该能得到更高的精确度(如,设置model_dim=256)。
可以发现迭代30次后,验证集精度达到了70%,由于数据集很小,通过缩小模型规模,应该能得到更高的精确度(如,设置model_dim=256)。
解码效果
1.直接解码decode_text_fast
 2.束搜索beam_search_text_decode
源句子如下:
`"Two women wearing red and a man coming out of a port @-@ a @-@ potty ."
符号@-@表示这是一个连接左右两词的连接符,即port @-@ a @-@ potty是一个词port-a-potty。这么做只是为了方便训练。
2.束搜索beam_search_text_decode
源句子如下:
`"Two women wearing red and a man coming out of a port @-@ a @-@ potty ."
符号@-@表示这是一个连接左右两词的连接符,即port @-@ a @-@ potty是一个词port-a-potty。这么做只是为了方便训练。
目标句子如下:
"Zwei Frauen in Rot und ein Mann , der aus einer transportablen Toilette kommt ."
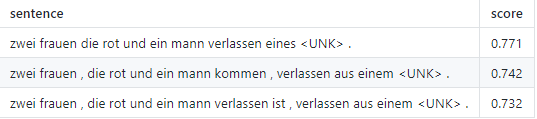
以束宽3经束搜索后的结果如下:
性能
性能测试时模型使用的配置与默认配置相同
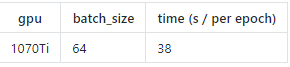
训练时性能
数据集包括 29000 个训练样例, 1014 个验证样例。
解码/翻译性能
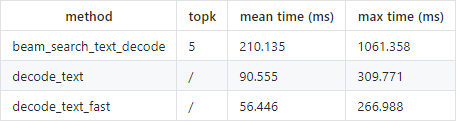 注意:最大耗时一般只发生在模型未训练时,即使用一个完全未训练的模型进行解码。
注意:最大耗时一般只发生在模型未训练时,即使用一个完全未训练的模型进行解码。
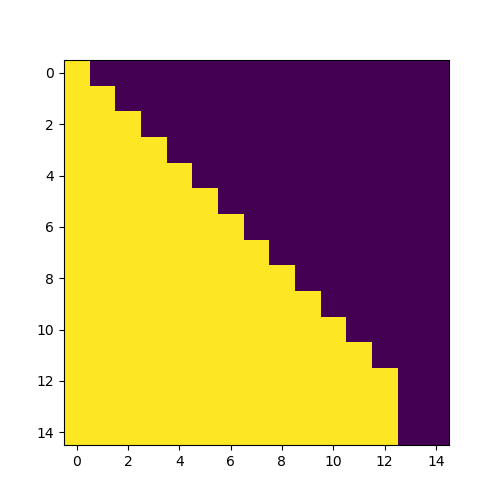
掩码可视化
example/mask_test.py

位置编码可视化
example/position_encoding_test.py
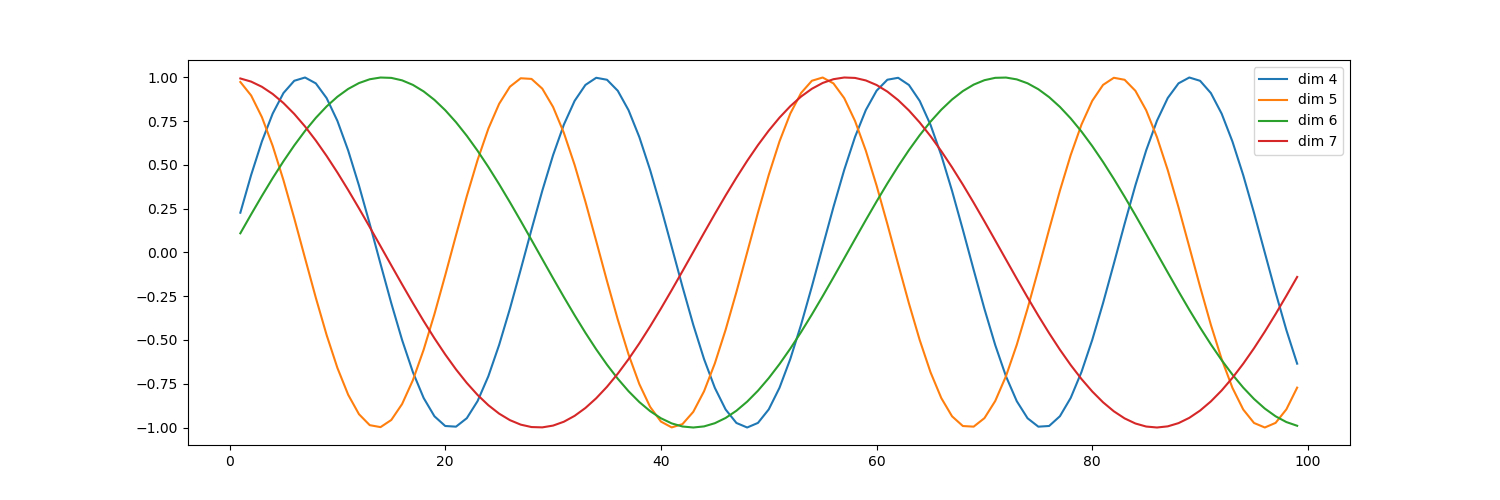
参考
1.https://github.com/Lsdefine/attention-is-all-you-need-keras 2.Transformer 模型的 PyTorch 实现 3.https://www.jiqizhixin.com/articles/Synced-github-implement-project-machine-translation-by-transformer 4.Setting the learning rate of your neural network
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250






