资源下载
资源下载


【项目】短文本聚类预模块

文件列表(压缩包大小 1.28M)
免费
概述
项目介绍
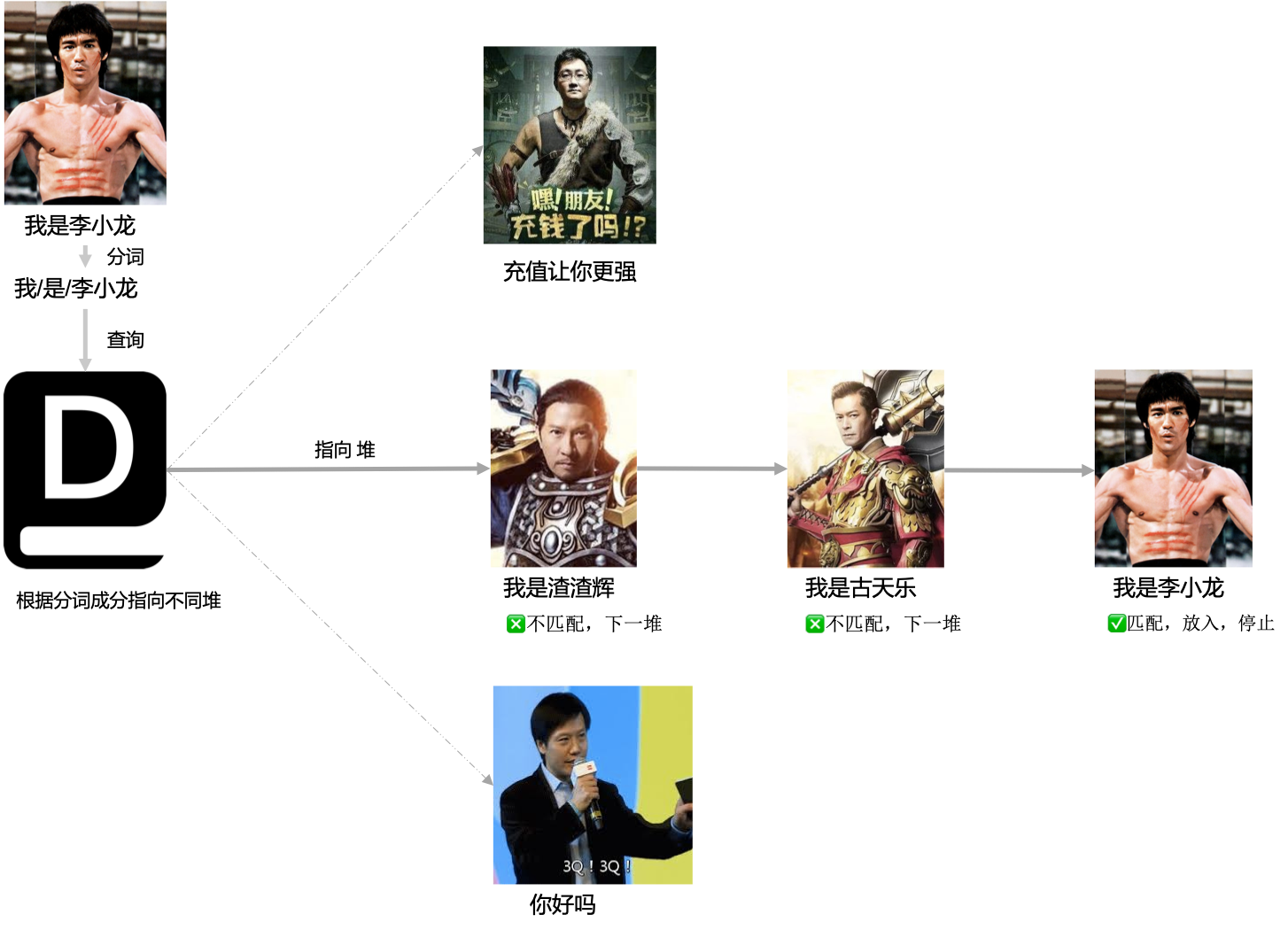
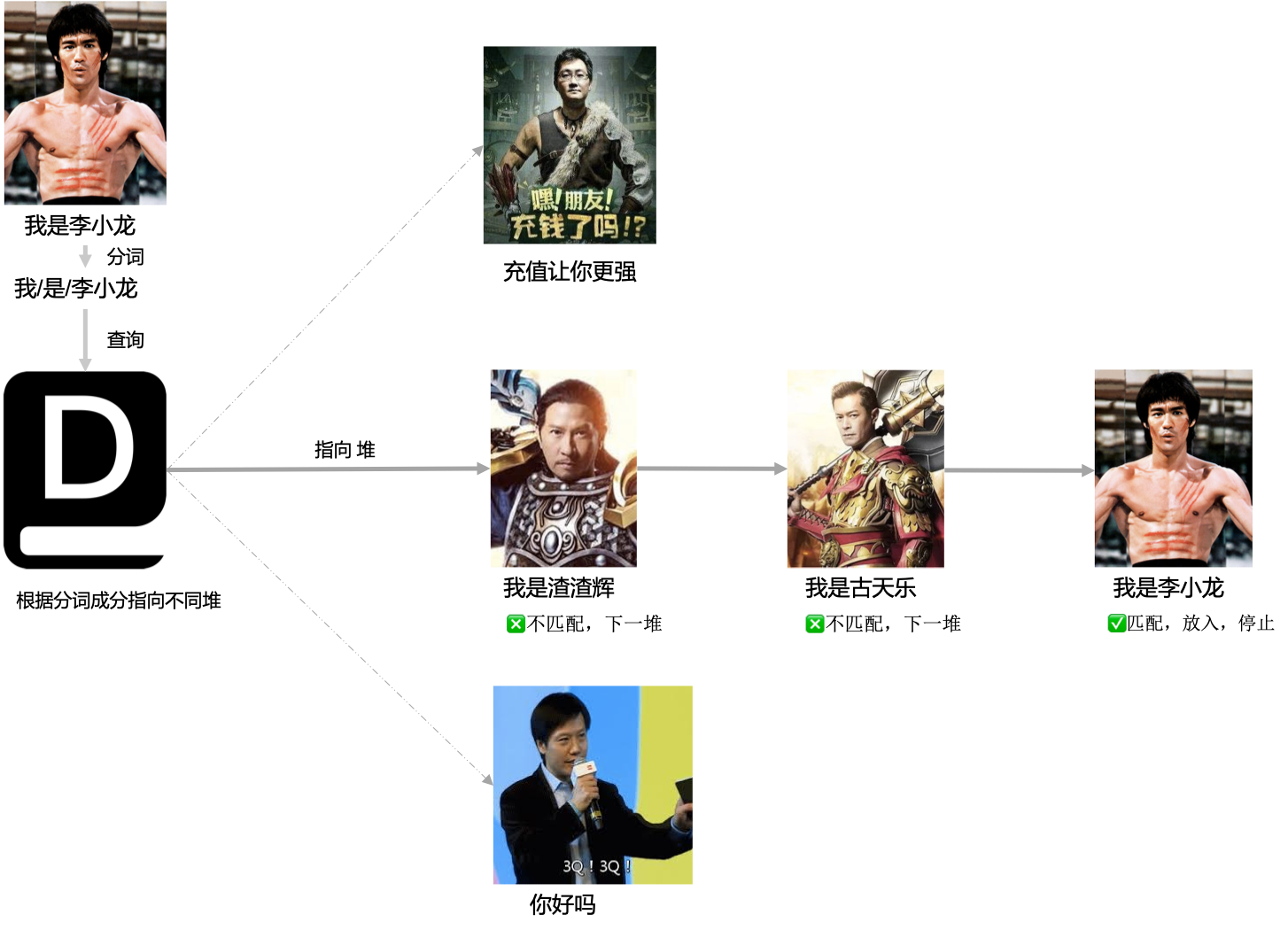
短文本聚类是常用的文本预处理步骤,可以用于洞察文本常见模式,分析设计语义解析规范,加速相似句查询等。查询接口。
依赖库
pip安装tqdm
使用方法
聚类
python cluster.py --infile ./data/infile \
-输出./data/output
具体参数设置可以参考cluster.py文件内部_get_parser()函数参数说明,包含设置分词词典,停用词,匹配采样数,匹配度阈值等。
查询
参考search.py代码里Searcher类的使用方法,如果用于查询标注数据的场景,使用分隔符:::将句子与标注信息分段起来。如我是海贼王:::(λx.海贼王),处理时会只对句子进行匹配。
算法原理
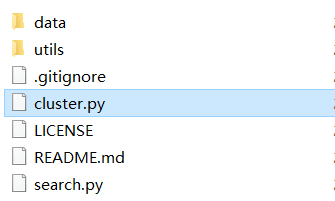
文件路径
TextCluster
| 自述文件
| 执照
| cluster.py聚类程序
| search.py查询程序
|
| ------ utils公共功能模块
| | init.py
| | segmentor.py分词器封装
| | 相似度计算函数
| | utils.py文件处理模块
|
| ------数据
| | infile默认输入文本路径,用于测试中文模式
| | infile_en默认输入文本路径,用于测试英文模式
| | seg_dict默认分词词典
| | stop_words默认停用词路径
注:本方法仅面向短文本,长文本聚类可根据需求替换SimHash,LDA等其他算法。
文字丛集
介绍
文本簇是分析文本特征的常规预处理过程。该项目仅对短文本集群实现了一种内存友好的方法。对于长文本,最好根据需要选择SimHash或LDA或其他
要求
安装tqdm spacy
用法
聚类
python cluster.py --infile ./data/infile_en \
-输出./data/output \
--lang en
有关更多配置参数的说明,请参阅_get_parser()中的cluster.py,包括停用词设置,样本号。
搜索
基本思想

档案结构
TextCluster
| 自述文件
| 执照
| cluster.py集群功能
| search.py搜索功能
|
| ------ utils实用程序
| | init.py
| | segmentor.py标记器包装器
| | similar.py相似度计算器
| | utils.py文件处理模块
|
| ------数据
| | infile默认输入文件路径,以测试中文模式
| | infile_en默认输入文件路径,以测试英语模式
| | seg_dict默认标记器dict路径
| | stop_words默认停用词路径
其他语言
对于其他特定语言,请在中修改令牌生成器包装器./utils/segmentor.py。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250