资源下载
资源下载

基于机器学习方法构建多因子选股模型

文件列表(压缩包大小 14.71M)
免费
概述
研究方法
单因子测试
确定一个单因子测试文件,定义待测因子列表,执行多次单因子runtest。
- 保留回测报告,获取字段,保存在CSV文件。
- 结果可视化。
- 筛选得到最优因子。
- 因子做共线性分析,获取最终因子。
使用 auto-trader软件提取沪深300成分股的日频数据和因子数据,在每一个时间横截面上使用上述模型进行最小二乘回归(WLS)。使用当期股票因子暴露值和下一期股票收益率做线性拟合。在进行因子测试时,由于要求每月月初进行调仓,因此以上一个月的各股票的因子暴露值作为自变量(第 T 期),上一个月各股票月平均收益率为因变量(第 T + 1期),拟合得到一个线性模型,然后将本月月初的股票因子值输入到拟合完成的线性模型,输出的各股票本月平均收益率进行选股回测。
数据采集
根据点宽网的BP因子数据字典,使用auto-trader软件提取股票日频因子数据。 样本范围:沪深300成分股,剔除停牌的等不正常股票。 样本期:2016年1月1日至2018年9月30日,按月进行提取。 因子选择:具体测试了基础科目衍生类、质量类、收益风险类、情绪类、成长类、常用技术指标类、动量类、价值类、每股指标类、模式识别类、特色技术指标、行业与分析师类共十二大类因子。为每一类的因子随机挑选了10~20个因子进行测试。由于挑选因子较多以及本文篇幅有限,部分表现较优的因子定义将会在回测部分进行显示。
选用机器学习模型回测
- 特征和标签构建。
- 等权重线性模型。
- 建立baseline models,尝试使用多种模型。SVR,RNN(LSTM),xgboost, random_forest,adaboost...
- 交易逻辑确定。
- 回测结果记录,分析。
关于模型的一些设想: 可参考论文GBDT提取特征 + SVM二分类的方法 LSTM进行选股(在月频数据较少,可能效果不好) Adaboost, randomforest, svm(启发式),xgboost等等进行集成。如Stacking,bagging.
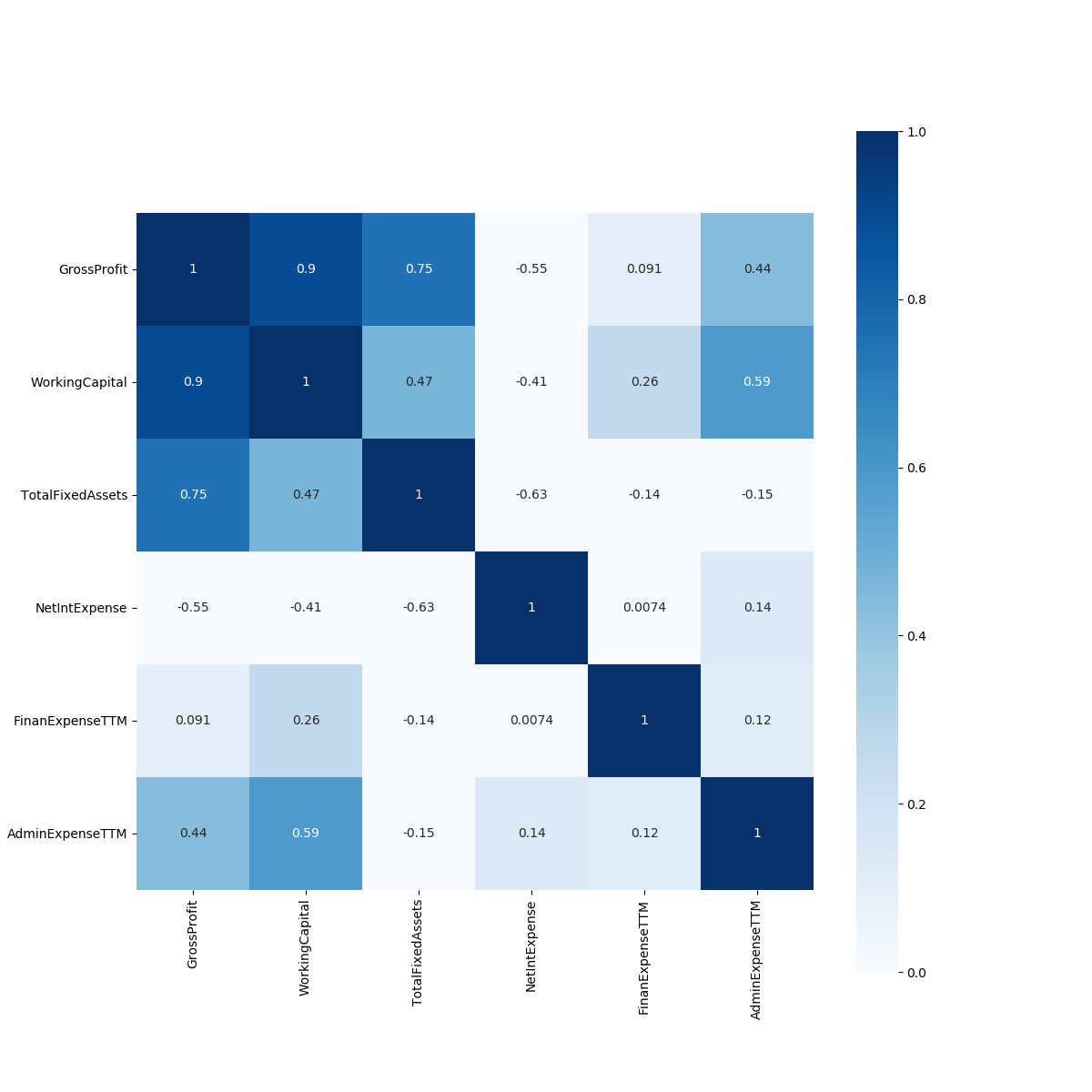
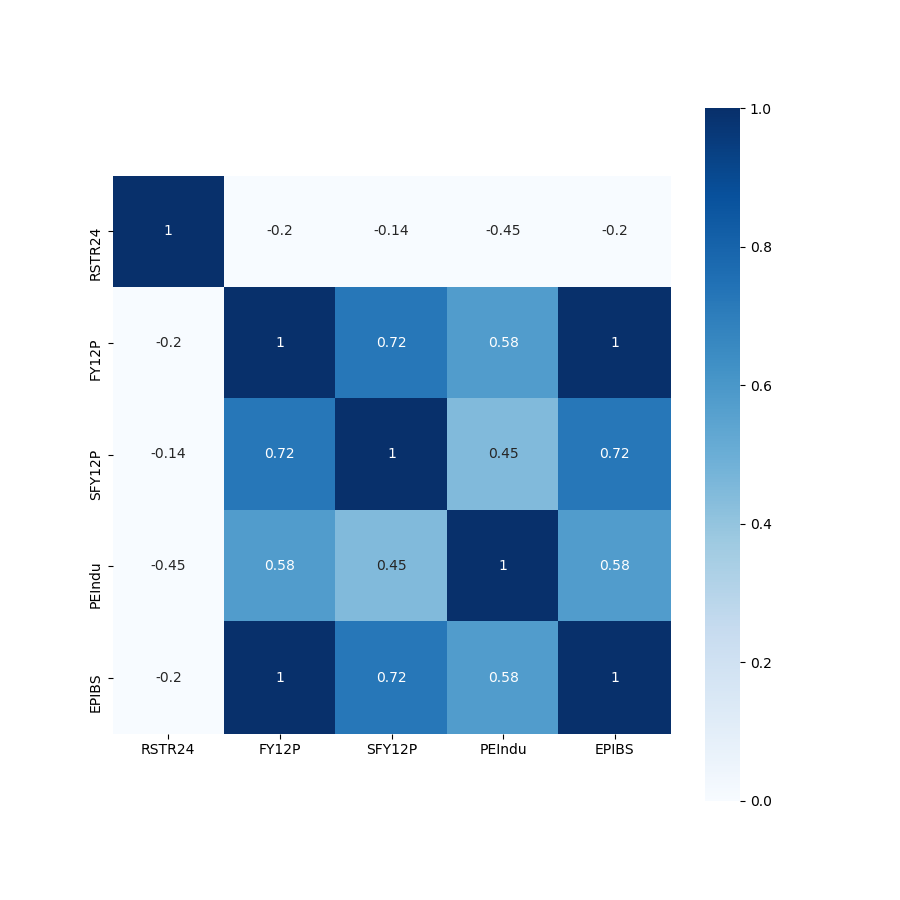
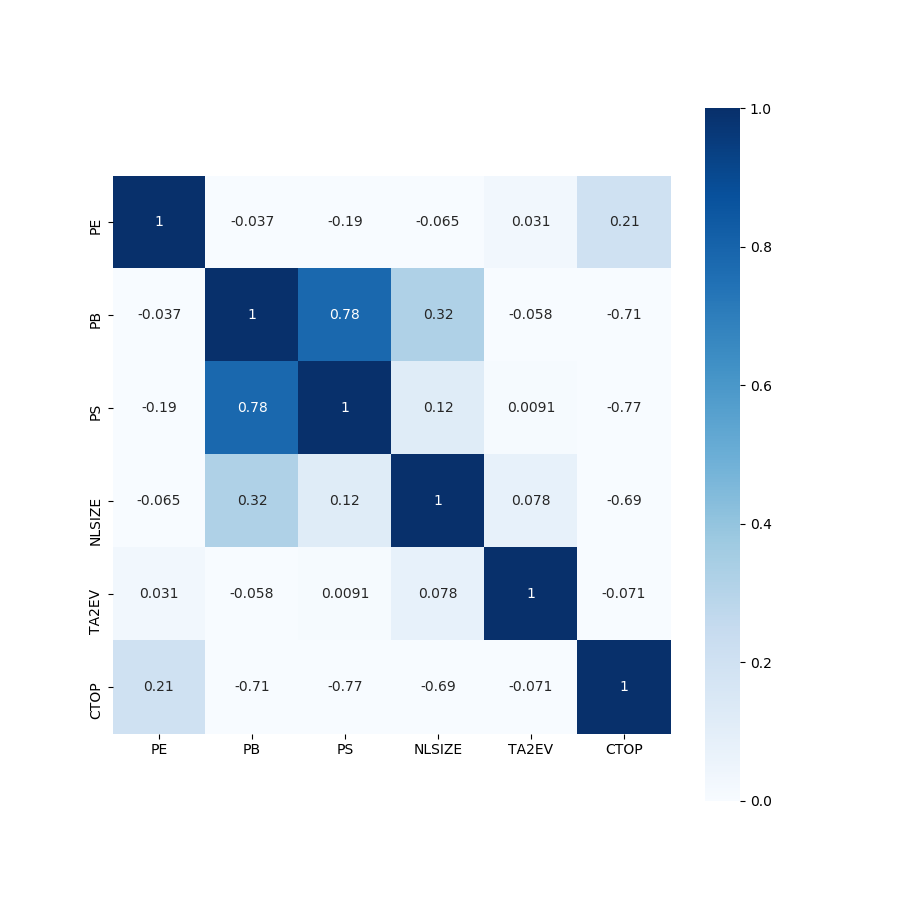
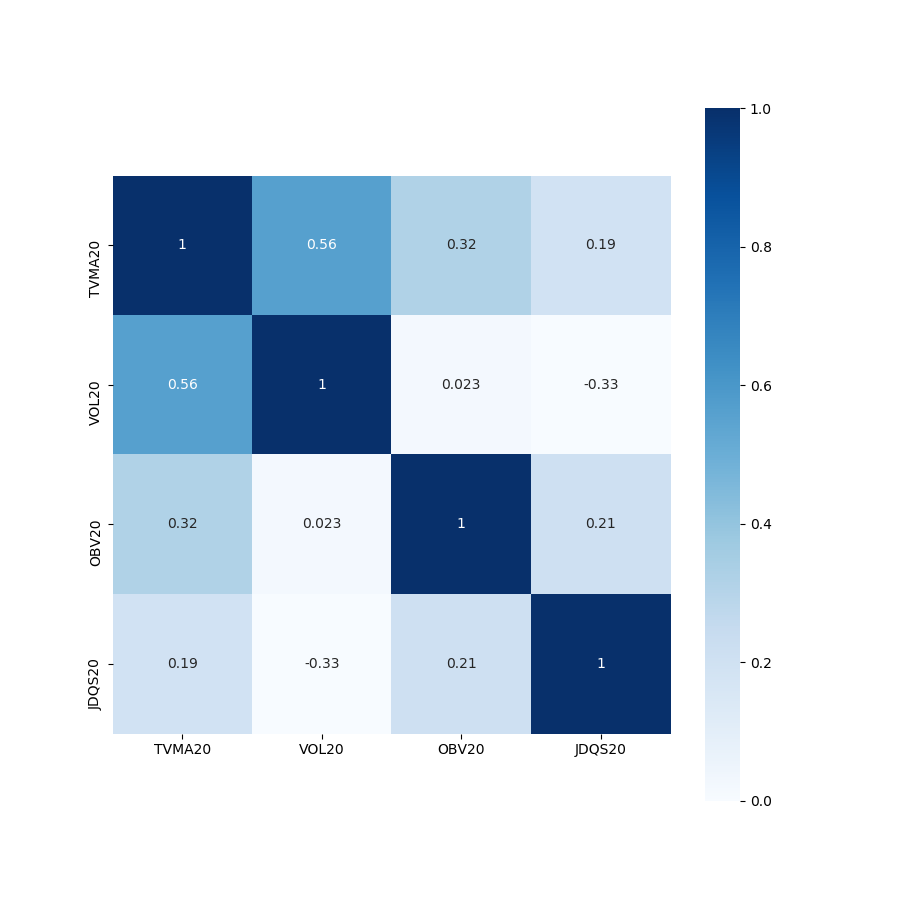
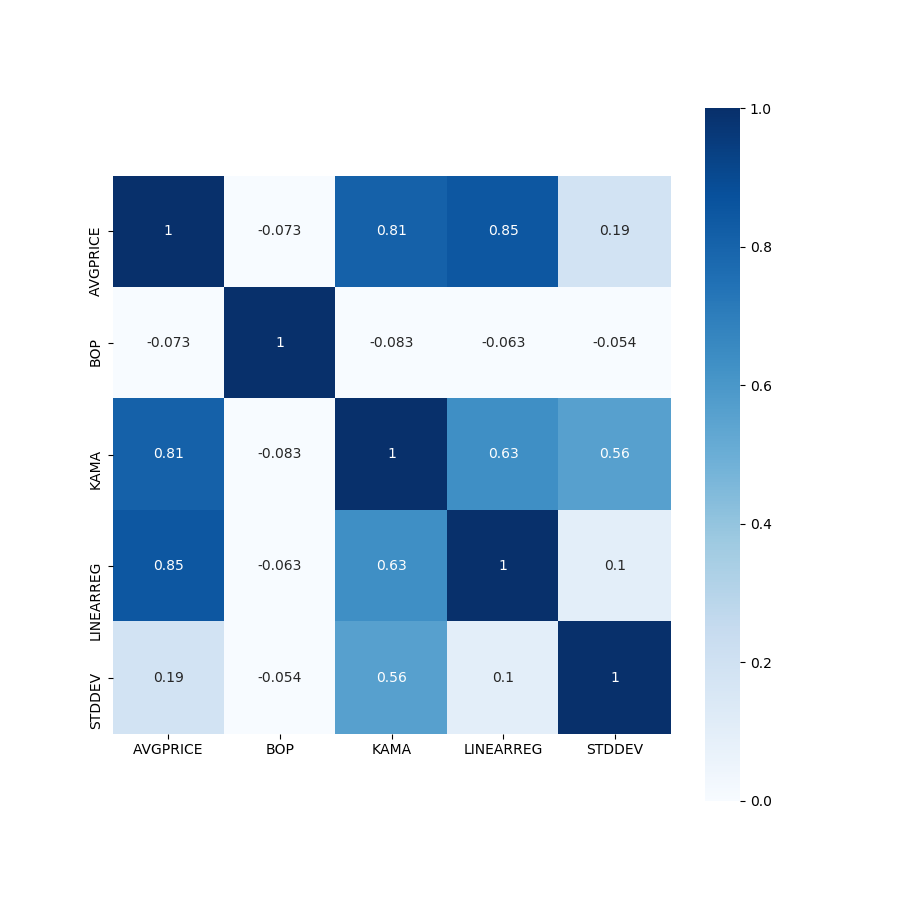
 按照上述思路,从各大类因子中随机挑选小类因子进行因子回测,得到每一个因子相应的回测报告数据,主要涉及策略的年化夏普率(以月为单位,等于夏普率×√12),年化收益率,最大回撤率,信息比率等指标。在进行因子筛选时,主要考虑因素为年化夏普率,优先筛选每一类中年化夏普率最高的因子,当存在较多表现较优的因子时,综合各方面指标进行筛选。同时为了解决因子的多重共线性问题,本项目测试了各大类因子间各因子历史序列的相关性,得到相关性矩阵,辨别出相关性较高的因子,对于这一类因子,采用因子剔除的方式进行处理。
按照上述思路,从各大类因子中随机挑选小类因子进行因子回测,得到每一个因子相应的回测报告数据,主要涉及策略的年化夏普率(以月为单位,等于夏普率×√12),年化收益率,最大回撤率,信息比率等指标。在进行因子筛选时,主要考虑因素为年化夏普率,优先筛选每一类中年化夏普率最高的因子,当存在较多表现较优的因子时,综合各方面指标进行筛选。同时为了解决因子的多重共线性问题,本项目测试了各大类因子间各因子历史序列的相关性,得到相关性矩阵,辨别出相关性较高的因子,对于这一类因子,采用因子剔除的方式进行处理。
风险控制
- 风险模型:barra模型
- 择时模型:三均线择时策略
文件说明
- data_exploration.ipynb: atrader API调用测试文件。
- get_factor_report.py: 当单因子回测结束之后,执行文件,得到策略字段。
- single_factor_test.py: 单因子测试文件。
- find_factor.py: 自实现的因子绩效分析文件(已弃用)
- run_test.bat: 脚本自动化运行python程序,实现多次执行策略。
- 'factor_analysis': 类内因子共线性分析文件,绘制相关系数矩阵。
以模型名标识模型回测文件。
项目成果
最优的随机森林模型:累计收益60%左右,经择时策略风险控制后,最大回撤率控制在9%左右,夏普率为0.9左右。 转载自:https://github.com/JoshuaQYH/TIDIBEI
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250