 资源下载
资源下载

使用scikit-learn时提高速度的三种主要方法是:使用joblib和Ray并行化或分发培训,使用不同的超参数优化技术(网格搜索,随机搜索,提前停止),以及更改优化功能(求解器)。
使用joblib和Ray并行或分发培训
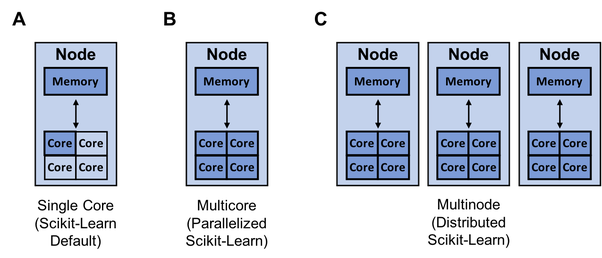 上图显示了scikit-learn可用于单核(A),多核(B)和多节点训练(C)的资源(深蓝色)。提高模型构建速度的一种方法是使用joblib和Ray并行化或分发培训。默认情况下,scikit-learn使用单核训练模型。当今几乎所有计算机都具有多个内核。
上图显示了scikit-learn可用于单核(A),多核(B)和多节点训练(C)的资源(深蓝色)。提高模型构建速度的一种方法是使用joblib和Ray并行化或分发培训。默认情况下,scikit-learn使用单核训练模型。当今几乎所有计算机都具有多个内核。
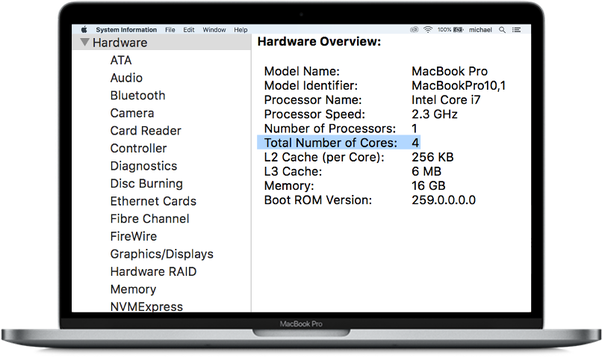 我们可以将上述MacBook视为具有4个核心的单个节点。因此,有很多机会可以利用计算机上的所有内核来加快模型的训练速度。如果模型具有高度的并行性(例如RandomForest®),则更应该如此。
我们可以将上述MacBook视为具有4个核心的单个节点。因此,有很多机会可以利用计算机上的所有内核来加快模型的训练速度。如果模型具有高度的并行性(例如RandomForest®),则更应该如此。
更改优化算法(求解器)
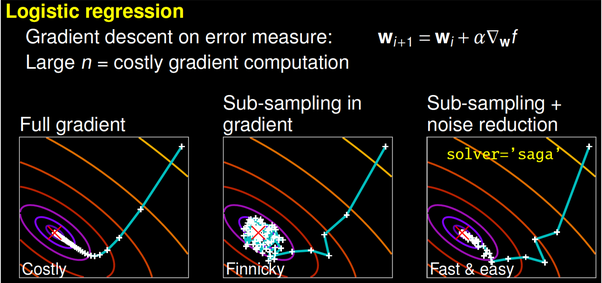 一些求解器可能需要更长的时间才能收敛(图片来自GaëlVaroquaux的演讲)。更好的算法可以更好地利用相同的硬件。使用更有效的算法,就可以更快地生成最佳模型。
一种方法是更改优化算法(求解器)。例如,scikit-learn的逻辑回归,可让在'newton-cg','lbfgs','liblinear','sag'和'saga'等求解器之间进行选择
一些求解器可能需要更长的时间才能收敛(图片来自GaëlVaroquaux的演讲)。更好的算法可以更好地利用相同的硬件。使用更有效的算法,就可以更快地生成最佳模型。
一种方法是更改优化算法(求解器)。例如,scikit-learn的逻辑回归,可让在'newton-cg','lbfgs','liblinear','sag'和'saga'等求解器之间进行选择
不同的超参数优化技术(网格搜索,随机搜索,提前停止)
Scikit-Learn本机包含用于超参数调整的几种技术像网格搜索(GridSearchCV,全面考虑所有参数组合)和随机搜索(RandomizedSearchCV,从具有指定分布的参数空间中采样给定数量的候选对象)。最近,scikit-learn添加了实验性超参数搜索估计量,将网格搜索(HalvingGridSearchCV)和随机搜索(HalvingRandomSearch)减半。 尽管这些新技术令人兴奋,但有一个名为Tune-sklearn的库提供最先进的超参数调整技术(贝叶斯优化,提早停止和分布式执行),可以大大提高网格搜索和随机搜索的速度。 转载自:https://www.quora.com/What-are-some-ways-to-optimize-for-more-speed-while-using-scikit-learn-in-Python






